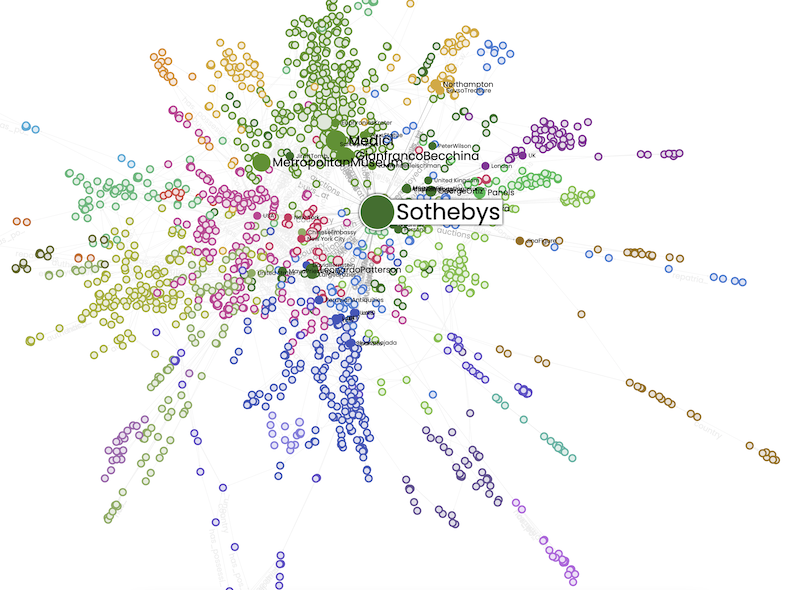
Colours = subgroups, size = betweenness.
Using the ontology crafted in the previous post I fed 129 Trafficking Culture articles through GPT4. I used a script to pass the ontology, with
You are an excellent assistant with deep knowledge of research in the field of illegal and illicit antiquities. Below is an ontology structuring knowledge about the field; using the ontology exclusively, please create specific instances and data about individuals within the antiquities trade from the following encyclopedia text.
followed by the ontology as my prompt.
This is the script to do that; note you have to make sure the texts you’re working on are about 6kb or smaller (so you need to split any that are larger into smaller pieces; you can do it by hand or by script):
import os
import sys
import openai
import tiktoken
from tenacity import retry, wait_random_exponential
def num_tokens_from_string(string: str, encoding_name: str) -> int:
"""Returns the number of tokens in a text string."""
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokens
def write_results_to_file(output_filename, content):
with open(output_filename, 'w') as f:
f.write(content)
# Add a delay function that waits between retries
@retry(wait=wait_random_exponential(multiplier=1, max=10))
def get_openai_response(prompt, input_text):
openai.api_key = os.getenv("OPENAI_API_KEY")
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{
"role": "system",
"content": prompt,
},
{
"role": "user",
"content": input_text,
},
{
"role": "assistant",
"content": ""
}
],
temperature=0,
max_tokens=4820,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
stop=["END "]
)
return response
def main():
if len(sys.argv) != 3:
print("Usage: python your_script_name.py prompt_file.txt input_file.txt")
sys.exit(1)
prompt_file = sys.argv[1]
input_file = sys.argv[2]
with open(prompt_file, 'r') as f:
prompt = f.read()
with open(input_file, 'r') as f:
input_text = f.read()
combined_text = prompt + input_text
encoding_name = "cl100k_base"
max_tokens_per_chunk = 2500
combined_tokens = num_tokens_from_string(combined_text, encoding_name)
print(combined_tokens)
if combined_tokens > max_tokens_per_chunk:
print(f"{input_file} skipped, too big!")
return
# Single chunk is within the limit, make the API call
print ("Working on " + input_file)
response = get_openai_response(prompt, input_text)
result_content = response["choices"][0]["message"]["content"]
output_filename = f"result_{input_file}.txt"
write_results_to_file(output_filename, result_content)
print("Done")
if __name__ == "__main__":
main()
Then I joined the results together at the command line with `cat *txt >> output.ttl` I added the prompt text (the original ontology) to the start of the output.ttl file to make sure everything was present and accounted for. Ta da, a ttl file of the antiquities trade!
But I wanted as csv for opening in gephi and so on. This little snippet does that:
import csv
from rdflib import Graph
def ttl_to_csv(ttl_file_path, csv_file_path):
# Parse the .ttl file with rdflib
g = Graph()
g.parse(ttl_file_path, format='ttl')
# Open the csv file with write privileges
with open(csv_file_path, 'w', newline='') as csv_file:
csv_writer = csv.writer(csv_file)
# Write the header row
csv_writer.writerow(["subject", "predicate", "object"])
# Iterate through each triple in the graph and write to the csv file
for s, p, o in g:
csv_writer.writerow([s, p, o])
After that, I just needed to clean out a handful of statements where things like my predicates were declared against a namespace, that sort of thing. All of which is available here. When I run it through Ampligraph, I get a pretty good MRR score too – without a lot of the futzing that I’ve had to do previously.
So the next thing to do is to run this process again, but against the 3k newspaper articles that we have. Pretty happy about this.