HAL9000 imagined as an archaeologist, via DiffusionBee
If you take a bunch of text, and drop it through a large language model, you can get what is called an ’embedding’ – a mathematical representation of where that text, that idea you wrote, is located within what the model ‘knows’. Other texts that get embedded get a location, too, and once you know where point A and point B are, it becomes possible to search that space for the closest points: you get a search engine bringing up ideas or content that inhabit the same multi-dimensional space.
Similarly, you can take an image and turn it into an embedding, and its location in that visual multi-dimensional space of the model becomes something you can explore to retrieve similar images.
But the really neat trick is when text and images are embedded in the same multidimensional space. ‘My cat is fat and is on the kitchen counter’ lies in close proximity to pictures, photos, and paintings of moggies on countertops. This is what powers those text-to-image generation models. Wouldn’t it be useful if you could take images that you have, and their associated captions, and build such a model for yourself?
Until fairly recently, that was a hard proposition for most people to do. Simon Willison has been developing a tool called ‘LLM’ which reduces a lot of the pain of working with large language models, and recently he released a new plugin for LLM that enables one to work with one of the older (I mean, a year or so old) image/text embedding models, CLIP. Using his tool, you can create a database of embeddings for a folder of images on your machine:
“`$ llm embed-multi photos –files photos/ ‘*.jpg‘ –binary -m clip“`
In this example, the command takes all of the jpgs in the folder ‘photos/’ and turns them into embedding vectors stored in a sqlite database called ‘photos’. (Having the vectors in the sqlite database allows for all sorts of other shennanigans that I’ll explore in a future post). At this point, searching for similar images is as easy as typing:
“`$ llm similar photos -c ‘raccoon‘“`
And you’ll get a list of the most similar photos plus their scores. Now, when Eric Kansa (Technology Director of Open Context) and I saw that, we got to talking. Wouldn’t it be great if we could search the over 2 million records Open Context has published over the last 17 years? What if you could search for ‘drawings of terracotta statuettes the date to the sixth century in either Turkey or Italy’?
Of Open Context’s 2 million records, around 77,000 are image records that describe artifacts. Each image is associated with artifact records describing styles, types, materials, and other characteristics. Most of these descriptions are inconsistent because they come from several different projects, each with different recording protocols. However, Open Context also annotates data with shared vocabularies as part of the editorial and publishing process. For example, the Getty Art and Architecture Thesaurus (as well as other metadata) provides more consistent description of this 77,000 image corpus.
Since this image corpus shares some common elements of description, we can (hopefully) train a machine-learning model to associate patterns in images with textual descriptions of artifacts. This can be used to enhance image search in Open Context and possibly even support AI image recognition services. It would be very cool to enable “reverse image search” features that allow you to upload an image (say of an unusual object discovered in excavation) to find possible comparanda that could aid with the object’s identification. There are probably many other applications that may also emerge.
So we set out to build our own variation on CLIP trained with Open Context data – the ArchaeCLIP model. Eric did a data dump and made it available to me, and I started trying to figure out how to fine tune the existing CLIP model with our data. The first thing I did was look to see if others had fine tuned CLIP and see if I could work out how they did it. And of course they had; there are many blog posts out there purporting to show you how to do things, and we started with this one. The most useful part of this process was seeing how people formatted their data before they tried to do the fine tuning. I turned my attention to that, but reshaping data can be kinda tricky if it’s not something you do everyday. I am not the world’s best coder. My strength lies in re-using other people’s (ideally well-formed and bug free) code, a kind of bricolage approach. But when I would find people’s code, inevitably, like magicians are wont to do, they always ‘forget’ to include an explanation of all the parts. The entire trick doesn’t get revealed. There’s always something that presumably a better coder than I would spot and know what to do, to fill the lacunae. I have taken to using a series of very careful prompts with GPT4 getting it to parse code or different elements of it for me when I needed to, and I would follow that up with very careful tweaking to see if what I thought I should be doing would actually work. I use GPT4 to map the landscape of my ignorance. A combination of careful exploration of Stack Overflow, and very tight prompting of GPT4 led me to develop a workflow that seemed to work – I could run my retrain_clip.py script and something would seem to happen. But… when you muck about training neural networks, you have to pay attention to the training loss values. These should go down rapidly at first and then start to level out. My training values always remained stuck, signalling that something wasn’t doing what it was supposed to do.
I shelved that problem, and with the output of my training process, I turned my attention to working out how to pass my (broken) retrained model to Simon’s llm-clip; I figured if I could at least do that then that would still move me forward. I would use llm-clip to create embeddings by passing images through my retrained model, and I would build my ‘search engine’ by using llm’s ability to pass text or an image to the model and retrieve the most similar results. This took a few days, and eventually I learned that you really just need to change one line of code in llm-clip.py to point to the location of your model – but your model needs to have a bunch of configuration files with it too. I figured out which ones these were, and lo! I could pass my broken fine-tuned archaeCLIP model and do searches with it.
At which point, I set it aside for a couple of days because I had an ugly dogs’ breakfast of code and I could not quite work out where the problem was. Was it that I wasn’t using enough training images? Was my training caption data (a merger of several different fields from the original data dump) too generic? I didn’t know and I was getting discouraged. My training code was very close to what I was seeing that other people had used, so I was very puzzled, but I knew something wasn’t right because one day, the script which had at least run starting throwing wild memory errors: I was gumming up the works on my machine.
I started over looking for examples of things that other people had done, and I found an example from Damian Stewart based on HuggingFace’s own documentation. I realized that part of my problem was that Simon’s LLM worked with HuggingFace’s sentence transformers to do the embedding, so things had to follow in that vein (there are any number of paths to achieve something, computationally, but you really need to know what you’re doing: reader, I often do not). This proved to be the path that we needed to take. I got that code working, ran it on my (not very literate) captions and a couple thousand images, and yes, yes it worked! I wrote another jupyter notebook for searching and keeping track of results. You can enter a query like ‘Metallic objects found in Central Italy’ and it will return coins, plaques and so on from Gabii. Or you can give it a picture of a particular kind of fibula and it will return images of things that look similar.
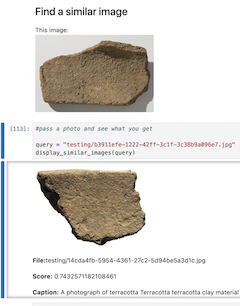
Reverse image search in action

Concept search in action
Eric has sent me better captions that use the cidoc-crm ontology to flesh out some of the ideas that describe the data, and I’m currently rerunning the training script. Then, I think with some of Simon Willison’s other tools, I can build a relatively light-weight website for people to explore the data for themselves (see what Drew Breunig achieved). We will also make the fine-tuned archaeCLIP model available for other people to use or play with, along with the whole workflow for doing this as painlessly as possible on your own data. As Eric writes,
[…]if we can make some progress with fine-tuning CLIP for archaeological image recognition, how could we build on this work? Could we expand it to include data from other sources beyond Open Context? How difficult would it be to compile comparable data from archaeological data repositories like tDAR or the Archaeology Data Service (ADS)?
[…]Also, some museums offer open data, including image data. How can we use machine learning with all of these data sources? In some ways, museum data may look very different from “field data” curated by Open Context. The data in Open Context mainly documents (let’s be honest) mundane ancient trash. In contrast, objects that enter into museum curation are typically much more special and rare– heavily biased to represent impressive works from elite, mortuary, or ritual contexts. Sometimes what we find in excavation may have once looked like those museum pieces, but they are a shadow (or a fragment!) of their former selves. Could an AI learn to recognize these as similar?
Considering the history and motivations behind museum collecting also raises important ethical questions. Many major museums have large and geographically diverse collections because of legacies of colonialism. Is it right to use digital representations of these “ill gotten gains” to fuel AI models? What kinds of governance and data sovereignty issues need to be addressed first?
These are all important questions to explore. AI feeds on data. Lots of data. Commercial interests are already heavily investing in these technologies. Archaeologists and other cultural heritage professionals need to engage in AI debates and voice our perspectives and ethical concerns in this rapidly developing sphere.
Stay tuned.
Update Oct 12
After training on ca 5k images from Open Context and another 1.5k images from the Metropolitan Museum of Art, I can say…. it works!
If you’d like to try things out for yourself, we have two Colab notebooks you can try.
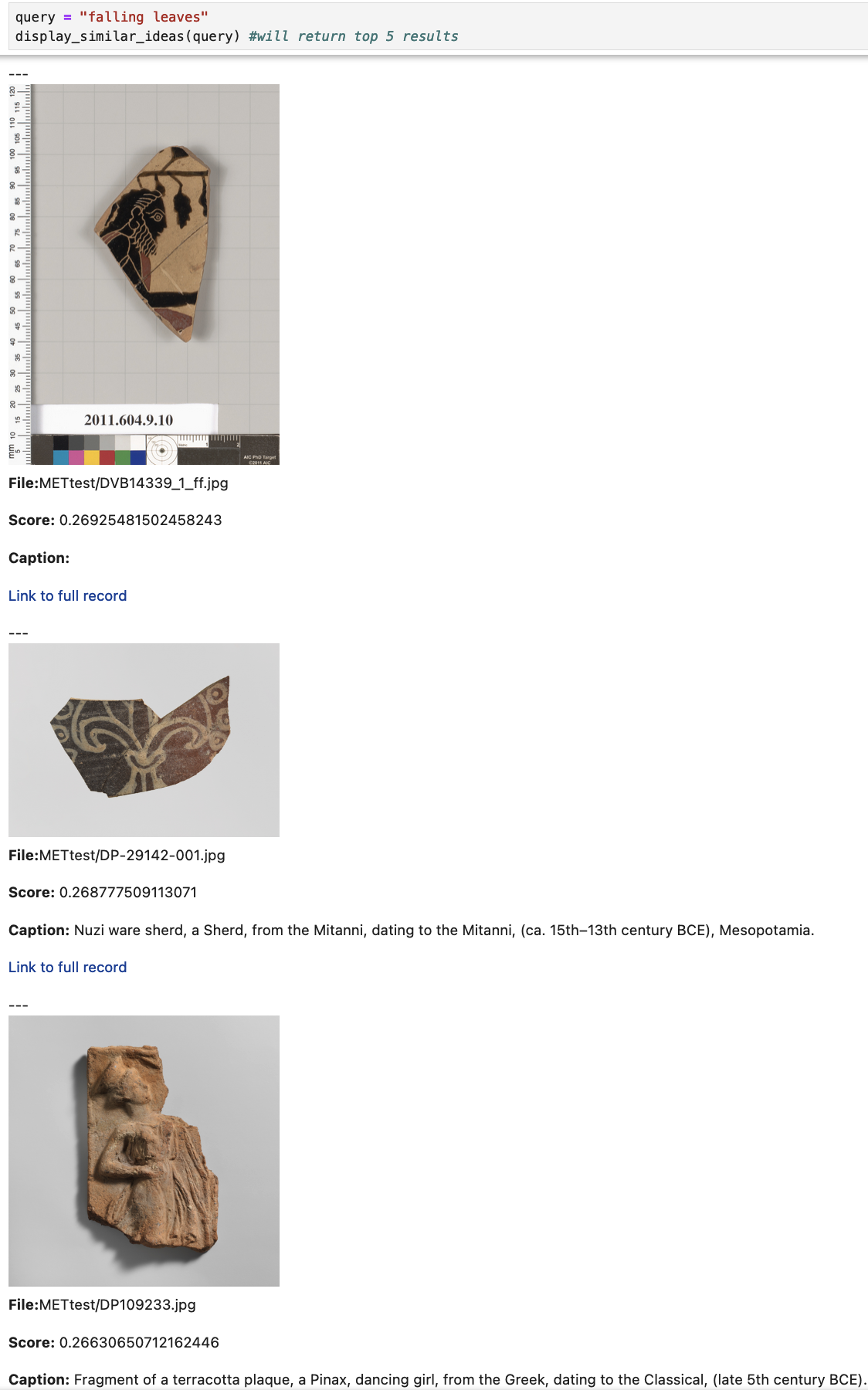
Run your own images through our model here This notebook will enable you to upload a folder of images and then create embeddings using our fine-tuned model. Then you can try searching for ideas like ‘falling leaves’ or ‘polychrome pottery from the sixth century’ (assuming perhaps that you have such things in your image data; otherwise, it will return the things that seem most similar; and on the value of not actually finding what you were looking for, see Mark Sample’s Your Mistake Was A Vital Connection).
Train your own fine-tuned CLIP model here This notebook will show you how we fine-tuned our model – it grabs images and metadata and arranges it the way it needs to be for the fine tuning to begin (You might prefer Damian Stewart‘s approach if you’ve got lots of local data to play with. Then it does the fine tuning. Once you get the config.json and the pytorch_model.bin files, you just have to organize them the way we do in the first notebook to use your own model with clip-llm. Have fun!