One of the things we’re working on in our group are ways to extract structured knowledge from lots of unstructured text. In an article coming out soon in Advances in Archaeological Practice, we demonstrate some of the things that we can accomplish when we have statements about a domain (in this case, the antiquities trade) arranged as subject, verb, object statements and then knit into a graph. The graph can be turned into a series of numerical vectors (think of each vector as a line shooting out in a different direction in a multidimensional space; call this a knowledge graph embedding model), and then we can make predictions about things we don’t know based on measuring the distances between those vectors. (We used a package called Ampligraph)
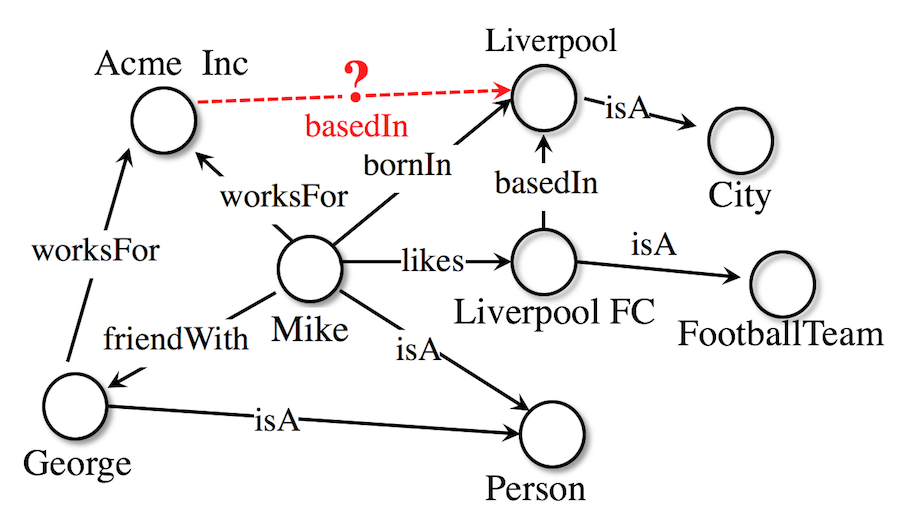
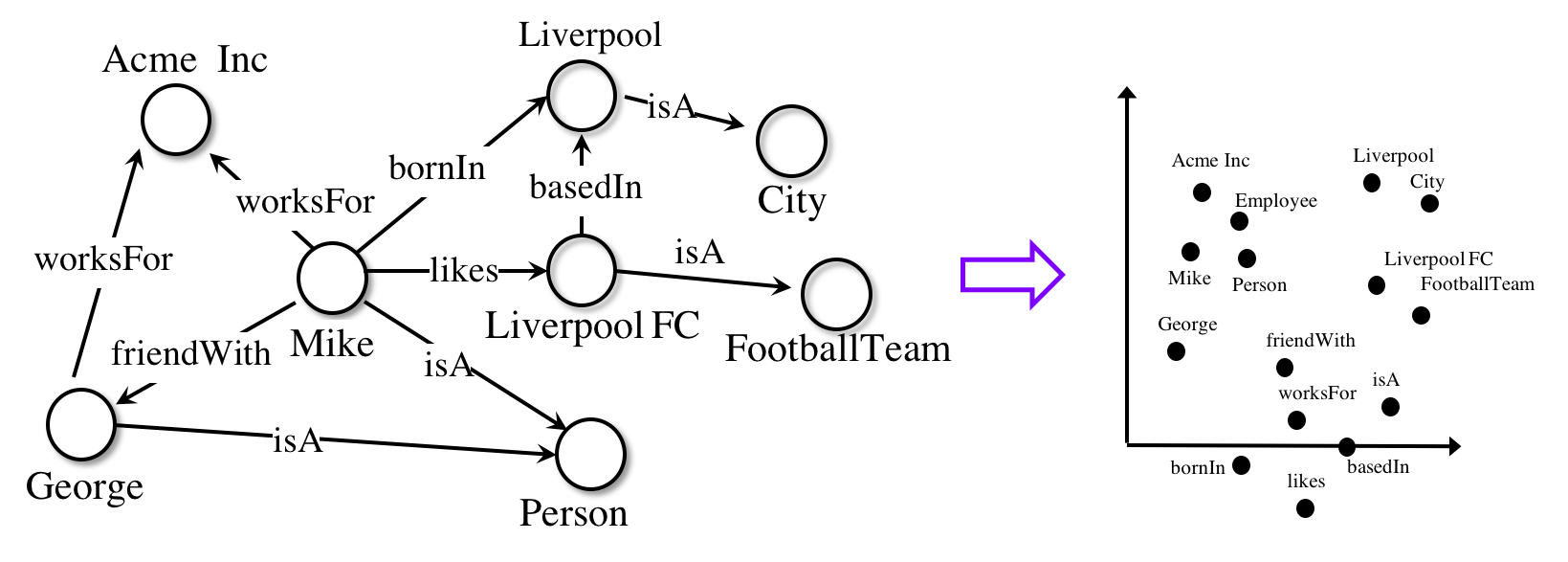
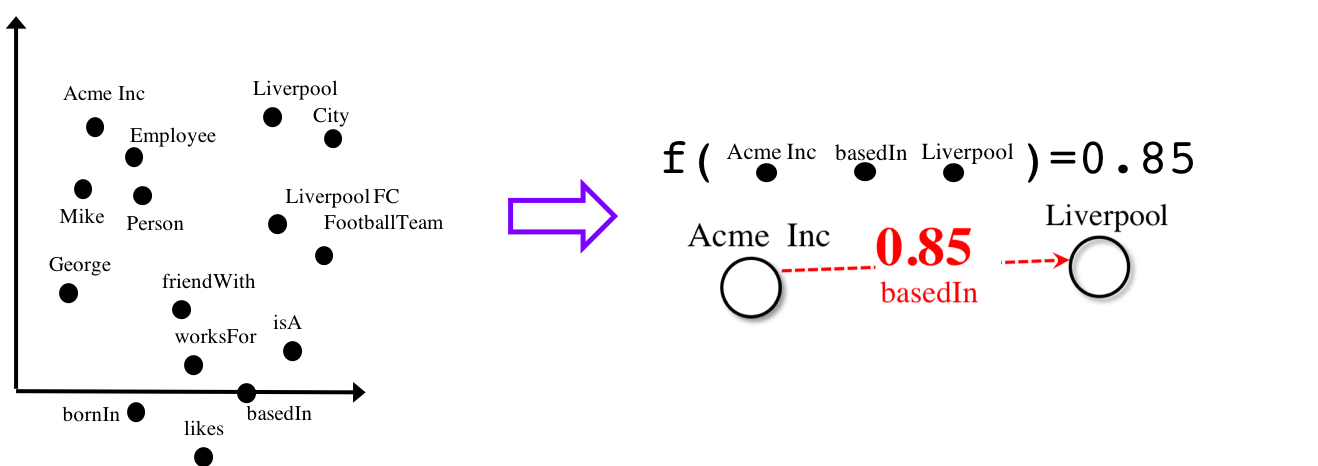
(illustrations of that process from Ampligraph)
But getting the knowledge out in the first place, from the text, so we can do something with it… that’s the hard part. We manually annotated 129 articles by hand (using a tool that used XML to indicate the relationship between the annotations and the text) and then Chantal wrote a script to turn those annotations into a CSV file. That took us several months. Surely there’s got to be a faster way?
We started playing with GPT3, the large language model that some fear will ruin education, others fear will put people out of jobs, and still some others figure will create jobs that don’t exist yet. We just wanted to know if it could identify subject, verbs, and objects from an article, selecting the most important bits. It can, and yes, it does feel spooky when it works. But it can make mistakes.
We adapted this tutorial so that we could pass one cell of data from a spreadsheet through the OpenAI API. Each cell contains the full text of an article we want to analyze. The script prepends a prompt to that text, and the prompt steers the generative power of the model in a particular direction. Having seen untold numbers of examples of internet texts that summarize movies, books, whatever, if you prompted the model with ‘Summarize this article’, you’d duly get a three or four line summary that captures the main point. What’s more, if you told it, ‘Summarize the text, but do it in the style of a 1940s gangster film where two gangsters are talking‘ and then gave it the text of this article about the Sarpedon Krater, you’d get:
Gangster 1: “Did ya hear ‘bout that krater they got at the Metropolitan Museum? Word is it was made in Athens like 500 years ago. They paid a million bucks for it!
Gangster 2: Yeah, I heard. Rumor has it they got it illegally in Italy, and then had to give it back. But it was all worth it – it made history!
While fun, gangster-speak isn’t what we’re after. Instead, we wondered, could we get GPT-3 to summarize these articles about the antiquities trade as a knowledge graph by generating the necessary code directly? Turns out, yes, yes you can.
We started with this prompt:
Write correctly formatted Cypher create and match queries to represent the knowledge graph of this text.
and it duly wrote,
CREATE (medici:Person {name:"Giacomo Medici"}),
(hecht:Person {name:"Robert Hecht"}),
(krater:Artifact {name:"Euphronios (Sarpedon) krater"}),
(romana:Gallery {name:"Antiquaria Romana"}),
(cleveland:Museum {name:"Cleveland Museum of Art"}),
(cooney:Person {name:"John Cooney"}),
(italy:Country {name:"Italy"}),
(medici)-[:STARTED_DEALING_IN_ANTIQUITIES_IN]->(italy),
(medici)-[:BECAME_SUPPLIER_TO]->(hecht),
(medici)-[:OPENED]->(romana),
(medici)-[:BOUGHT]->(krater),
<snip>
Code above dropped directly into Neo4j
This code works! The problem though is that if you run a second article through the OpenAI API that mentions some of the same individuals, objects, places, or organizations, there’s no memory of the previous time. So you’ll get different variable names being created for the same figure, and so multiple nodes in your graph that are actually the same person or thing. We think we can get around this problem though by carefully framing the prompt with a few limited examples (the longer the prompt text, the shorter the response, so that’s also a concern).
This is what we’re working with at present, which seems to handle things with only a few errors that can be cleared up manually afterwards:
Write a correctly formatted Cypher create query
to represent first key individuals, organizations, and objects,
then the appropriate relationships between them.
Check to see if a node exists before creating it;
ALWAYS derive the variable name from the first initial plus the name.
Here is an example of the desired output:
MERGE (gfb:Individual {name: 'Gianfranco Becchina'})
MERGE (gkk:Object {name: 'Getty Kouros'})
CREATE (gfb)-[:ACQUIRED]->(gkk)
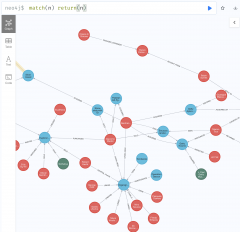
The screenshot below is the result after running four articles mentioning the figure of Giacomo Medici (from the Trafficking Culture Project Encyclopedia) through our prompts; total elapsed time to get the Cypher statements: about 3 minutes.
We’ve still got some kinks to figure out, but it’s exciting to see this (mostly) working. Once the graph is built, we’ll be able to query it too using natural language instead of Cypher – we’ll just ask GPT3 to translate our questions into suitable code.
Things to Read
https://neo4j.com/developer-blog/explore-chatgpt-learning-code-data-nlp-graph/
https://towardsdatascience.com/gpt-3-for-doctor-ai-1396d1cd6fa5