Simon Willison’s LLM package is a lovely little command line utility that allows you to work with many different large language models. In this post, we use LLM to extract a knowledge graph from a mermaid diagram sketch.
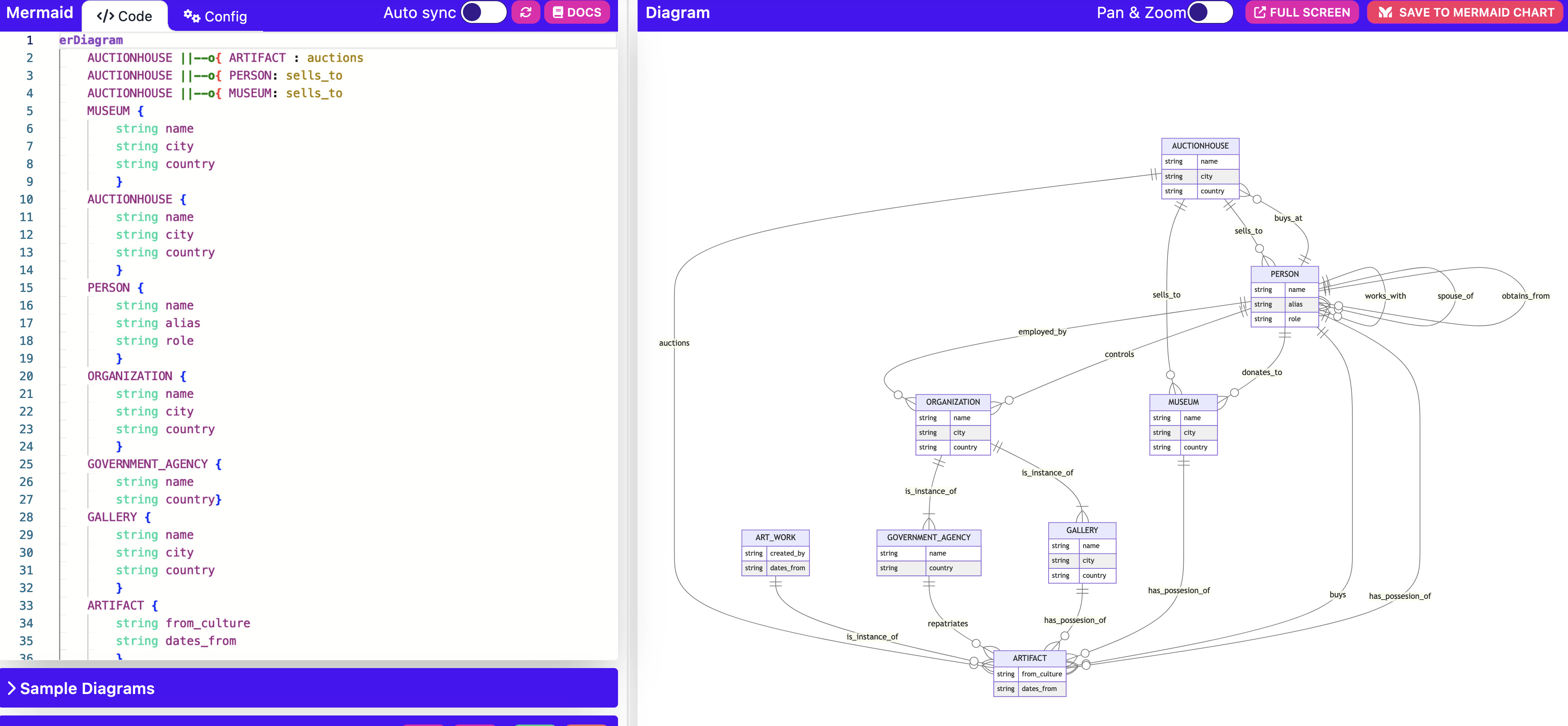
1. Sketch out the basics of your knowledge graph. On paper – yes, on paper! It’s quicker that way. What kinds of entities do you have? What are their properties? What are the relationships between the entities, and what are their properties? Once you have this sketched, you can translate the sketch into the more formal language of an entity relation graph using the mermaid conventions.
erDiagram
AUCTIONHOUSE ||--o{ ARTIFACT: auctions
AUCTIONHOUSE ||--o{ PERSON: sells_to
AUCTIONHOUSE ||--o{ MUSEUM: sells_to
MUSEUM{
string name
string city
string country
}
AUCTIONHOUSE{
string name
string city
string country
}
for instance specifies some relationships between auction houses and artifacts, persons, and museums; then, we specify some of the properties of MUSEUM and AUCTIONHOUSE and so on.
I write my diagram at https://mermaid.live/edit so I can also see the result, making sure it conforms to my initial sketch:
2. I install LLM into a new python environment. Assuming you’ve created your environment, at the terminal:
$ pip install llm
3. I install the llm-gpt4all plugin which makes a number of models optimized to run on consumer grade machines available:
$llm install llm-gpt4all
You can then see what’s available by running:
$llm models list
If you want to use any particular model, you just use the name from that list after the -m flag; the first time you use it, it will download the relevant model. Test it now:
$llm -m orca-mini-7b '3 names for a pet cow'
Now, for our purposes, we want to use that sketch of the ontology of the antiquities trade as the guide for the model. We want the model to do one thing, and one thing well: identify entities and their properties, and the relationships that we’ve already specified in the sketch. To do that, we’ll make a template file.
4. Find the templates directory: $llm templates path . Open your code or text editor of choice. Create an empty file called extract.yaml and save it in that folder. We’re now going to define a system key, which will tell the model what kind of persona to adopt, and a prompt key which will tell it what to do. Here’s mine. Notice you can use variables in your template; in mine, I have $input for the text being processed. Here’s more about templates and variables; I no doubt could be more elegant here.
5. Now that we have a model downloaded, and a template to guide it, we’ll run it against a file. We can grab webpages and feed them directly to the model using a combination of tools such as curl and Willison’s strip-tags utility, which would be really elegant. However, I already have a folder with the information I’m after on my machine. To feed a single file to the prompt we use the cat command:
$cat giacomo.txt | llm -m 4 -t extract > outputgraph.csv`
That one-liner says take the text file called giacomo.txt and run it through the GPT4 large language model using extract.yaml as the prompt and guide then write the output to outputgraph.csv.
We get:
1. ("Giacomo Medici", "sells_to", "Sotheby’s London")
2. ("Sotheby’s London", "auctions", "Onesimos kylix")
3. ("Hydra Gallery", "sells_to", "Sotheby’s London")
4. ("Christian Boursaud", "works_with", "Giacomo Medici")
5. ("Giacomo Medici", "works_with", "Robert Hecht")
6. ("J. Paul Getty Museum", "buys", "Onesimos kylix")
7. ("Robert Hecht", "buys", "Euphronios (Sarpedon) krater")
8. ("Giacomo Medici", "sells_to", "J. Paul Getty Museum")
9. ("Giacomo Medici", "controls", "Hydra Gallery")
10. ("Giacomo Medici", "obtains_from", "Christian Boursaud")
11. ("Medici", "has_posession_of", "Euphronios (Sarpedon) krater")
12. ("Editions Services", "is_instance_of", "ORGANIZATION")
13. ("Giacomo Medici", "controls", "Editions Services")
14. ("Sotheby’s", "auctions", "looted Apulian vases")
15. ("Sotheby’s", "sells_to", "J. Paul Getty Museum")
16. ("Sotheby’s", "sells_to", "Metropolitan Museum of Art")
17. ("Sotheby’s", "sells_to", "Cleveland Museum of Art")
18. ("Sotheby’s", "sells_to", "Boston Museum of Fine Arts")
19. ("Maurice Tempelsman", "buys_at", "Sotheby’s")
20. ("Shelby White", "buys_at", "Sotheby’s")
21. ("George Ortiz", "buys_at", "Sotheby’s")
22. ("José Luis Várez Fisa", "buys_at", "Sotheby’s")
23. ("Lawrence Fleischman", "buys_at", "Sotheby’s")
24. ("Giacomo Medici", "sells_to", "Barbara Fleischman")
25. ("Medici", "has_possesion_of", "sarcophagus")
26. ("Medici", "has_possesion_of", "illegally-excavated artefacts")
27. ("Giacomo Medici", "sells_to", "Maurice Tempelsman")
28. ("Giacomo Medici", "sells_to", "Shelby White")
29. ("Giacomo Medici", "sells_to", "Leon Levy")
30. ("Giacomo Medici", "sells_to", "George Ortiz")
31. ("Giacomo Medici", "sells_to", "José Luis Várez Fisa")
32. ("Medici", "donates_to", "J. Paul Getty")
Ta da! A knowledge graph. To iterate over everything in our folder, we can use this one-liner:
$find /path/to/directory -type f -exec sh -c 'cat {} | llm -m 4 -t extract' \; >> outputgraph.csv
replacing /path/to/directory of course.
Now we could specify that the output follow turtle rdf conventions, in which case we would also get all of the properties for the entities and relationships. To do that, we change the prompt portion of our extract.yaml:
prompt: 'Extract ONLY entities as indicated in the pattern, and ONLY predicates as indicated in the pattern. Return subject, predicate, object triples, as an ontology using RDF-Turtle for the input text, using the following guidelines: 1 – Denote subjects and objects using relative hash-based hyperlinks i.e., negating the use of example.com. 2- Output response to a code-block. 3 – Place ## Turtle Start ## and ## Turtle End ## around the code within the code-block. etc.
erDiagram
AUCTIONHOUSE ||--o{ ARTIFACT : auctions
We could specify that the output be written as cypher statements, meaning we could load the data directly into a Neo4j database. Another important thing to note is that all interactions are logged to a local sqlite database for further use; see https://llm.datasette.io/en/stable/logging.html. If you have datasette installed, you can explore the results of your experiments by running datasette "$(llm logs path)"
Handy, eh?