So far in our experiments with knowledge graphs and large language models (see here,and here ) we’ve been content to work with the unstructured text and let the data model, such as it is, to percolate up from below, trying to impose a bit of structure on it afterwards by seeing what subject – predicate – object triplets emerge, and working with the most common predicates.
No doubt this is not the best way to go about it. Today we came across this post by Peter Lawrence where he used an RDF ontology in ttl format as part of his GPT-3 prompt against unstructured text to see if that would make his extracted knowledge graph more rigorous. He found that it did; so we thought we’d give it a try too. You can see the transcript of his chat here.
Our problem of course is that we do not have a well-specified ontology. But we figured, as part of its training, that chat gpt has probably seen – let’s be frank – far more examples that any of us have ever encountered. So we fired up chatgpt to see what we could see.
Here was our initial prompt:
> In the illegal antiquities trade, people buy and sell antiquities that may have been stolen or looted. Police investigate them and make arrests. Museums buy antiquities from collectors, dealers, and auction houses. Archaeologists investigate sites that may have been looted. Dealers might be collectors. There might be other relationships, as well. Provide a well-formed and complete definition of the illegal antiquities trade as an RDF ontology in TTL format.
and chatgpt started churning stuff out:
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix ex: <http://example.org/ontology#> .
# Classes
ex:IllegalAntiquitiesTrade rdf:type owl:Class ;
rdfs:label "Illegal Antiquities Trade" ;
rdfs:comment "The trade involving the buying and selling of antiquities that may have been stolen or looted." .
ex:Person rdf:type owl:Class ;
rdfs:label "Person" ;
rdfs:comment "A human being involved in the antiquities trade." .
[…]
So far, so good. We would drop the result into a rdf visualizer to check how things were going, what entities and relationships it was cooking up; very rarely were there any syntax errors that borked it, but sometimes it would ‘forget’ elements it had included in previous rounds. These we would re-add by hand, show the complete thing to it again, ask it to critique what was present and what was absent. We went through a couple of iterations of that process. Here’s a shot of the visualization step in action: 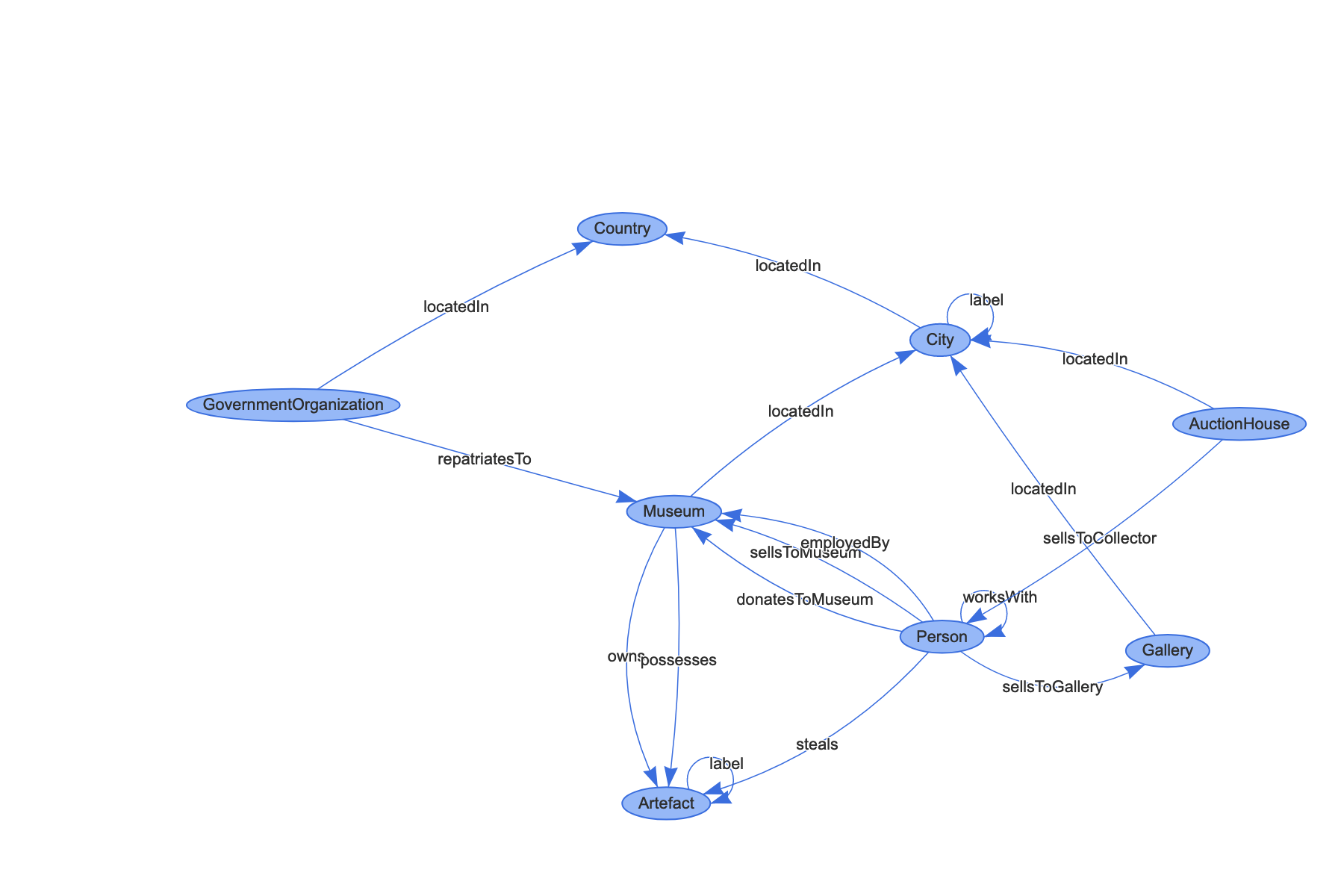
Once we arrived at something that seemed pretty good, we moved onto the next step (where we could follow Peter Lawrence’s example more closely). We fed chatgpt3 another prompt that instructed it to use our ontology against some of the text from the Trafficking Culture entry on Giacomo Medici:
Using this provided ontology exclusively, please create specific instances and data about individuals within the antiquities trade from the following encyclopedia text. Also create the RDF graph. TEXT: Giacomo Medici is an Italian antiquities dealer who was convicted in 2005 of receiving stolen goods, illegal export of goods, and conspiracy to traffic. Note: Seized images of illicit antiquities which lead to the eventual conviction of Medici can be found in our Tracking Illicit Antiquities section […].
Visualizing the resulting file on a quick rdf visualization website, we got this:
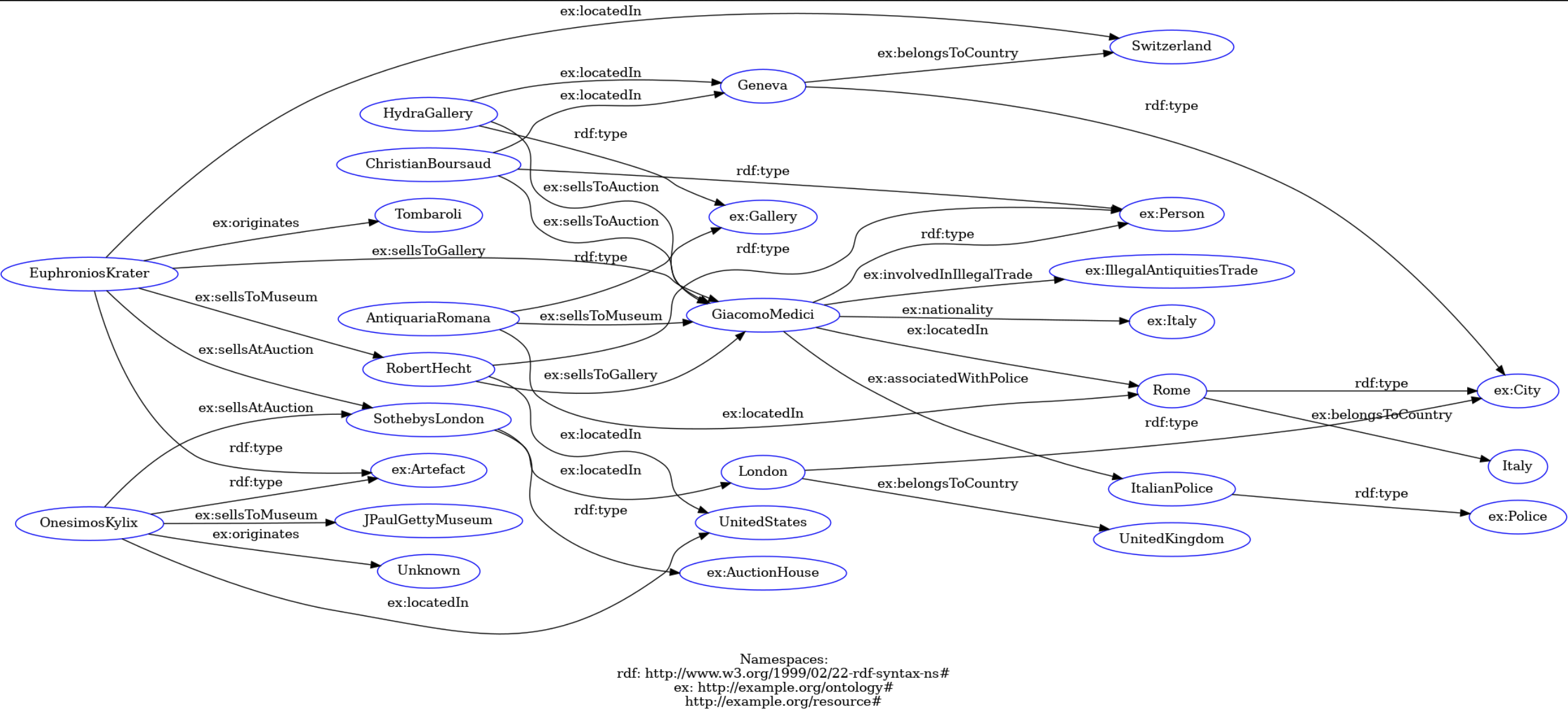
…which more or less looks like what we’re after, though the directionality of things is a bit off, Medici isn’t a gallery, etc:
:RobertHecht rdf:type ex:Person ;
ex:sellsToGallery :GiacomoMedici ;
ex:locatedIn :UnitedStates .
:AntiquariaRomana rdf:type ex:Gallery ;
ex:sellsToMuseum :GiacomoMedici ;
ex:locatedIn :Rome .
:ChristianBoursaud rdf:type ex:Person ;
ex:sellsToAuction :GiacomoMedici ;
ex:locatedIn :Geneva .
so that’s something we can fiddle with. These triplets can be fed into Ampligraph, so our hope is that this approach might be less error-prone and more rigorous than what we’ve been up to. Only one way to find out…
…unless of course this is another one of those situations where ChatGPT gives you almost what you’re looking for, but the final jiggerypokery of that last 10% ends up eating all your time and energy. At any rate, now that we’ve got a good start on an ontology, we can probably bring it into something like Protégé for fixes or otherwise manually edit it to get it to where we need it to be.
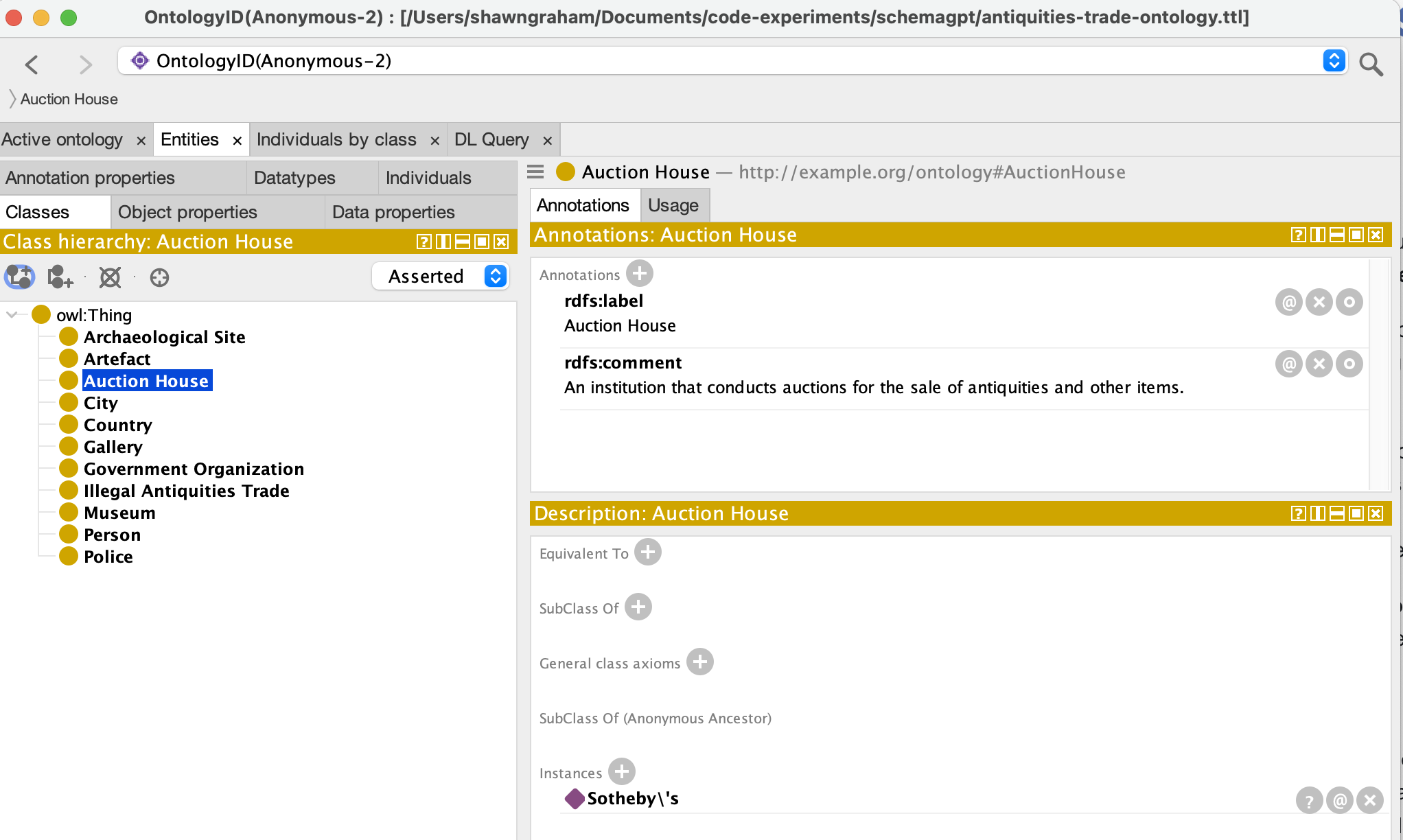
Our ontology loaded into Protege