Research Software Development
Research Software Development
The Research Software Development team works with researchers to develop purpose-built software based on their needs in order to further their research programs. If you believe this service would be of value to you, please contact RCS. If you use the any custom software produced with the help of the Research Software Development team as a part of your published research, it would be greatly appreciated if you could acknowledge RCS in your publication. Note: all Research Software Development projects are subject to our Standard Intellectual Property Terms and the Research Software Development team reserves the right to publicize any project on which they participate.
Support and Maintenance
If the intended research development project will be running as a service hosted by Carleton University, the underlying systems that ITS already supports (VM, operating system, database, webservers, etc.) will follow ITS’ current maintenance schedule. The support for underlying systems hosted outside of Carleton or those that Carleton does not support will fall to the host provider or the researcher to perform regular software updates.
The software development team will work closely with the researcher during development to ensure all of the project goals are completed. Once the software is formally handed over to the researcher, support and maintenance in the form of bug fixes, feature improvement, etc. will be done on a best-effort basis and by request only. To allow for the Research Software Development team to provide long term support to researchers long after the software was initially developed, the team will stick to a core set of relevant technologies and fully document each project to allow for easier knowledge transfer.
Software Licensing
Software for research is highly reusable and producing well-architected, well-written, fully tested, and properly documented code not only helps the individual researcher but contributes to the research community as a whole. In this spirit, the code generated by the Research Software Development team will be licensed under the GNU General Public License, a Free and Open Source Software (FOSS) licence whenever possible and appropriate. Once a project has reached a suitable state, the code will be released on the public RCS Github page.
Projects
A list of projects contributed to by the Research Software Development team, along with links to the publicly available open source code, is given below. Please click each project for more information.
-
In Canada and elsewhere, biological diversity – and the many cultural, economic and aesthetic benefits it provides us – is under threat. Protecting and carefully managing land is the most important thing we can do to reduce this threat. However, decisions of where and how to protect and manage lands are always difficult, especially where high biodiversity overlaps with many competing interests. Prof. Joseph Bennett from the Department of Biology is partnering with a Nature Conservancy of Canada (NCC) team led by Dr. Richard Schuster to co-design user-friendly decision support tools for land acquisition, stewardship and monitoring. NCC will use these tools to make its acquisition and stewardship planning more efficient, and to harmonize its goals and processes nationally. The team is also developing public-facing tools that can be used by government agencies, municipalities and land trusts to help manage their land use.
The Research Software Development team has supported this research by enhancing existing widgets and implementing new widgets for the front-end of the Conservation Decision Tools, a user-friendly platform for land acquisition, stewardship, and monitoring. The front-end is built upon R Shiny. Technologies used include: JavaScript (including the jQuery and D3.js – Data-Driven Documents libraries), CSS (including Bootstrap) and HTML.
-
In Canada and elsewhere, biological diversity – and the many cultural, economic and aesthetic benefits it provides us – is under threat. Protecting and carefully managing land is the most important thing we can do to reduce this threat. However, decisions of where and how to protect and manage lands are always difficult, especially where high biodiversity overlaps with many competing interests. Prof. Joseph Bennett from the Department of Biology is partnering with a Nature Conservancy of Canada (NCC) team led by Dr. Richard Schuster to co-design user-friendly decision support tools for land acquisition, stewardship and monitoring. NCC will use these tools to make its acquisition and stewardship planning more efficient, and to harmonize its goals and processes nationally. The team is also developing public-facing tools that can be used by government agencies, municipalities and land trusts to help manage their land use.
The Research Software Development team has supported this research by enhancing existing widgets and implementing new widgets for the front-end of the Conservation Decision Tools, a user-friendly platform for land acquisition, stewardship, and monitoring. The front-end is built upon R Shiny. Technologies used include: JavaScript (including the jQuery and D3.js – Data-Driven Documents libraries), CSS (including Bootstrap) and HTML.
-
Misinformation related to public health advice is a problem that social media companies have tried to address throughout the pandemic. Despite efforts to take down or block obviously false information, misleading or inaccurate information about the COVID-19 vaccines has continued to proliferate. Our project tries to understand this problem by moving beyond an approach that treats online discourse about vaccines in a true/false binary. By collecting and analyzing Twitter data, our project identifies some of the underlying cultural themes that are most often associated with questionable information about vaccines. The study combines qualitative annotations of individual Tweets with automated text analysis to decipher the key cultural themes driving vaccine misinformation.
The Research Software Development team has supported this research by designing and implementing the twitter annotator platform as a modern web application. This modern and secure web application is a platform for collecting and analyzing Twitter data, and combines qualitative annotations of Tweets. Technologies used for the web application include: JavaScript (including React and Redux), Python (including Flask) and Keycloak.
Source code:
-
Prof. Prof. Ba Chu from the Department of Economics at Carleton University is interested in using Natural Language Processing, a type of artificial intelligence, and print media to develop insights into stock market dynamics. He has collected a large textual data set (over 2TB) containing all free-subscription online newspapers in English collected over the period from 2016 to 2022. Before this vast trove of data could be utilized it first needed to be analyzed for useful articles and organized into collections depending on research goals. For one research project Prof. Chu was interested in studying sentiment in the United States at the state level. The RCS team assisted by developing tools to automate web searching for lists of local state newspapers. The list of local newspapers was then used to sort articles in his collection by state. For another project, Prof. Chu was interested in looking for articles which commented directly on specific company’s stocks. For this the RCS team developed efficient search algorithms to identify articles which contain one or more stock symbols from a list of over 19 thousand possibilities. Had a brute force search been employed, the search would have taken an exorbitant amount of time. By capitalizing on specific patterns in the news reports on stocks and distributing the task over multiple processors the search time was substantially reduced. The main technologies utilized for these project were the Python (including the Beautiful Soup library which enabled web-scraping of state newspaper directories).
Source code:
-
Similar the the previously described project, here Prof. Prof. Ba Chu from the Department of Economics in interested in investigating how sentiment specific to individual cryptocurrencies can be used to forecast future returns over time. This was accomplished using large language models (LLMs) to analyze and extracte sentiment indices from articles focused on specific coins. These sentiment insights were then used to develop potentially profitable trading strategies. The Research Computing Service supported Professor Chu by developing code to compare sentiment indices generated from different prompts and LLMs, enhancing the analysis and refining the models’ effectiveness.
-
Aptamers are short DNA or RNA sequences that are able to recognize and bind to target molecules with high affinity and specificity. The process for discovering new aptamers, called SELEX, has been very successful, however the conditions under which the experiment is run can vary from researcher to researcher and may have a dramatic impact on aptamer properties. The purpose of this project, led by Prof. Maria DeRosa from the Department of Chemistry, was to develop a database for housing aptamer selection experiment conditions and to allow for querying of these conditions to help unravel their effect on aptamer properties. This resource is available online at aptamerbase.carleton.ca.
The Research Software Development team has supported this research by designing and implementing the “Aptamerbase” database platform as a modern web application. This modern and secure web application is a database management system for housing and managing the Aptamer data. Technologies used for the web application include: JavaScript (including React and Redux), Python (including including Flask, SQLAlchemy and Marshmellow), PostgreSQL and Keycloak.
Source code:
-
The text data mining project, lead by Prof. Ahmed Doha of the Sprott School of Business, aims to collect the text of research papers from journals contributing to the field of business and management. This data to create ontologies and data models that can help researchers make more effective and efficient use of this data in applications like literature review assistance.
The Research Software Development team has supported this research by writing an application to download article information (full text pdfs, various pieces of metadata) for specific publishers from Crossref, an online repository for research publication information. The code uses the researcher’s ORCID credentials to allow access to this data. The source code for this project can be found on our public Github page below. Technologies used include: Python (including the Beautiful Soup, Pandas and Requests libraries).
-
Prof. Steve Fai from the Azrieli School of Architecture & Urbanism and the director of the Carleton Immersive Media Studio (CIMS) leads the Ontario East 3D (OE3D) project which brings together Building Information Modelling (BIM) and Geographic Information Systems (GIS) with open and proprietary data sets to represent and manage multi-dimensional graphic and semantic assets related to a geospatially large (50,000+km²), non-urban environment in Eastern Ontario. One of the primary objectives of the project was to develop a web-based, three-dimensional application that could be used to create, manage, and valorize digital assets related to the agri-food industry in the region.
Initially, the OE3D project was developed using a combination of web technologies including a backend ExpressJS API server, a frontend React application, and a PostgreSQL database. The backend API server was responsible for handling requests from the frontend application and interacting with the database to fetch and update data. The frontend application was built using React and was responsible for rendering the 3D model and providing an interactive user interface.
However, as the project evolved, it became clear that the existing architecture was not scalable and did not meet the performance requirements for handling large datasets. The RCS software development team decided to migrate the project to a new architecture using NextJS, a React framework that provides server-side rendering and static site generation capabilities. In addition, the login and registration functionality were migrated from the PassportJS JWT technology to the NextAuth library, to simplify the authentication process and improve security. Further, the client-side data caching was improved upon by eliminating React state management library Redux and using the NextJS built-in data fetching methods to pre-render pages with data. This change significantly improved the performance of the application and reduced the load on the server.
To summarize, the migration to NextJS and the use of NextAuth for authentication provided a more efficient and scalable architecture for the OE3D project. The new architecture also allowed for better separation of concerns, with the frontend and backend code being more modular and easier to maintain. The new architecture allowed for better performance, improved security, and a more streamlined development process. The use of server-side rendering and static site generation also improved the user experience by providing faster load times.
The new OE3D web application is currently being embedded in a larger web application, all of which will be released in the near future. Below are some screenshots of the upgraded OE3D web application.



-
Artificial intelligence (AI) is on the rise with many countries around the world investing greatly in AI to boost their economies. However, many experts caution that this rapid growth in development and application of AI in every aspect of life, without properly mitigating its risks may eventually have devastating consequences for humanity. The for-profit sector, which is playing a huge role in development and application of AI is mainly unregulated on AI accountability. The purpose of this study, lead by Prof. Maryam Firoozi of the Sprott School of Business, is to understand if and how firms in North America disclose information related to development and application of AI and whether this information has any substance. The outcome of this research will advance our understanding of AI disclosure as a mechanism for AI accountability.
The Research Software Development team has supported this research by developing a Python script that takes as input a list of websites and a list of keywords. Each website in the list is crawled and searched for the occurrence of each keyword. The script works by first downloading the HTML of a website. The HTML is then searched for text and links. The text is searched for occurrences of the keywords, and the links are checked against a list of already visited sites. For each new link found, the process is run again. In this way all the links within the website’s domain are crawled and searched. By implementing this search in parallel, the RCS team reduced the execution time from days to hours. Moreover, this script has eliminated the daunting and time-consuming task of manually inspecting the websites for keywords. The source code for this project can be found on our public Github page below. Technologies used include: Python (including the requests_html, Pandas, urllib, and PyPDF2 libraries).
Prof. Firoozi encountered further challenges with this research. Extracting text from highly structured PDFs in proper reading order can be challenging. Highly structured documents contain text in columns of various shapes and widths, as well as background and font colours. Extracting text directly from the file can suffer from improper ordering of text blocks, and intentional obscurification from the document author. Other techniques such as optical character recognition (OCR), though able to deal with intentional obscurification, can not cope with varying widths and shapes of text columns, or font and background colours. To overcome these issues this the RCS team implemented a tool that uses a mixture of OCR and classical computer vision segmentation techniques to extract text from highly structured documents in proper reading order. Technologies used include: Python (including the Tesseract and OpenCV libraries.
-
The intention of this project, lead by Prof. Maryam Firoozi of the Sprott School of Business, was to do a comprehensive literature review of research on Artificial intelligence (AI) in Accounting and Finance. Both fields have been significantly impacted by the rapid adoption of AI systems. The purpose of this project is to synthesize research on AI in these two fields and to provide direction for future research.
The literature review was automated using the Elsevier API. A total of 126 keyword searches of 397 journals was performed. Resulting in over 5000 journal articles spanning the 24-year period between 2000 and 2024. Source code for this project will be released once the research has been published.
-
Permafrost underlies more than one-third of the Canadian land surface. Most of this is expected to experience significant loss of subsurface ice over the next 100 years and beyond, leading to irreversible landscape transformations, design and maintenance challenges for infrastructure and threats to the health of northerners. The NSERC Permafrost Partnership Network for Canada (NSERC PermafrostNet), lead by Prof. Stephan Gruber from the Department of Geography and Environmental Studies, will develop better spatial estimates of ground-ice content and geotechnical characteristics, improve representation of key phenomena and processes in models, and provide simulation results at scales commensurate with observations.
The Research Software Development team has supported this research by designing and implementing an interactive browser for permafrost data. This modern and secure web application provides access and visualizations of data sets from a variety of sources and offers a shared set of tools for the permafrost research community. This resource can be accessed at pdsp.permafrostnet.ca. The source code for the various aspects of this project can be found on our public GitHub page at the links below. Technologies used include: JavaScript (including React and Redux), Python (including Flask, SQLAlchemy and Marshmellow), PostgreSQL and Keycloak.
Source code:
-
Professor Hoffmann of the Economics Department and School of Public Policy and Administration is conducting an experiment to understand how people’s awareness of how their actions contribute to climate change affects their travel decisions. She plans to recruit 6,000 online survey respondents in Canada and the US to take part in the study.
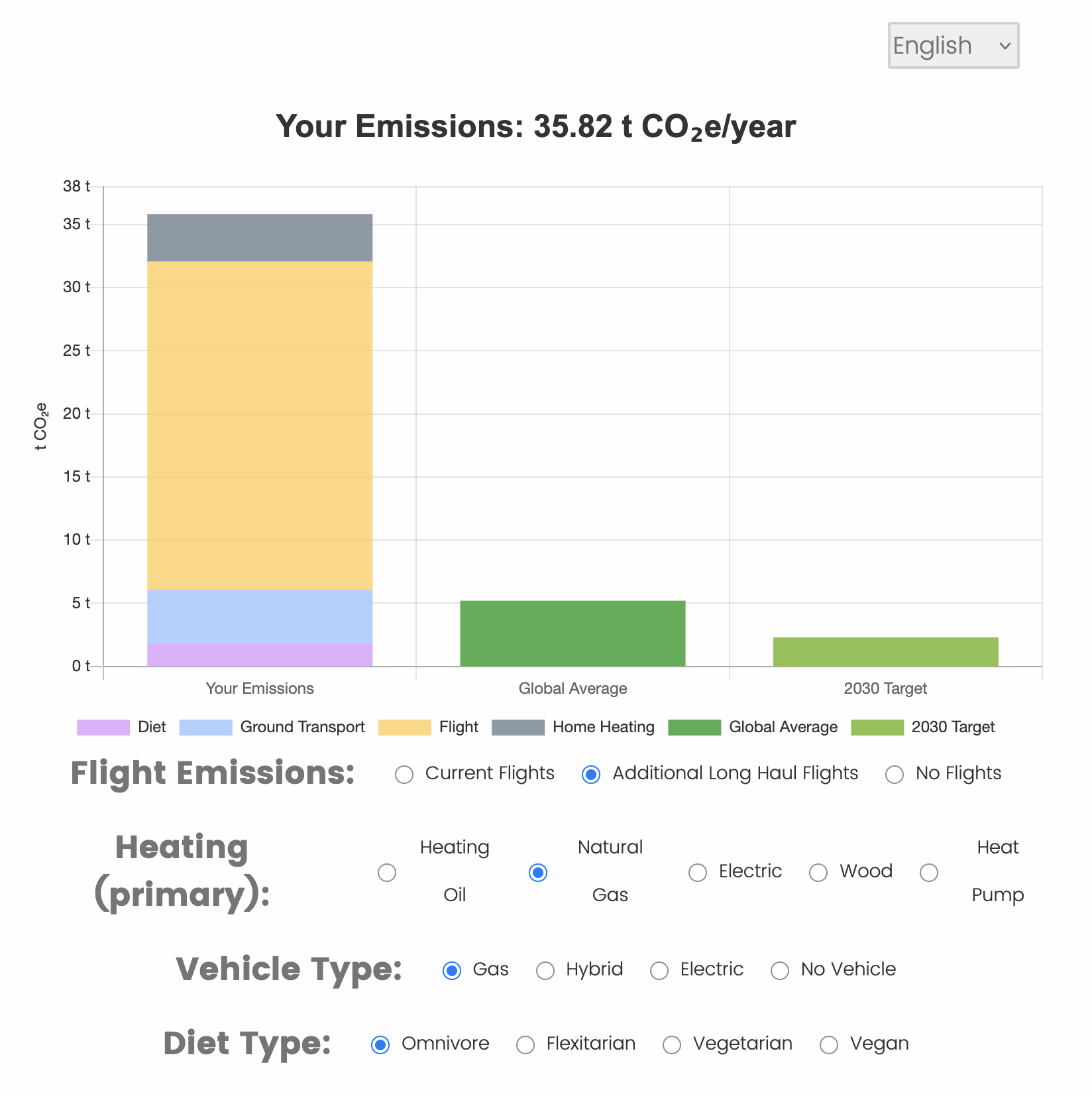
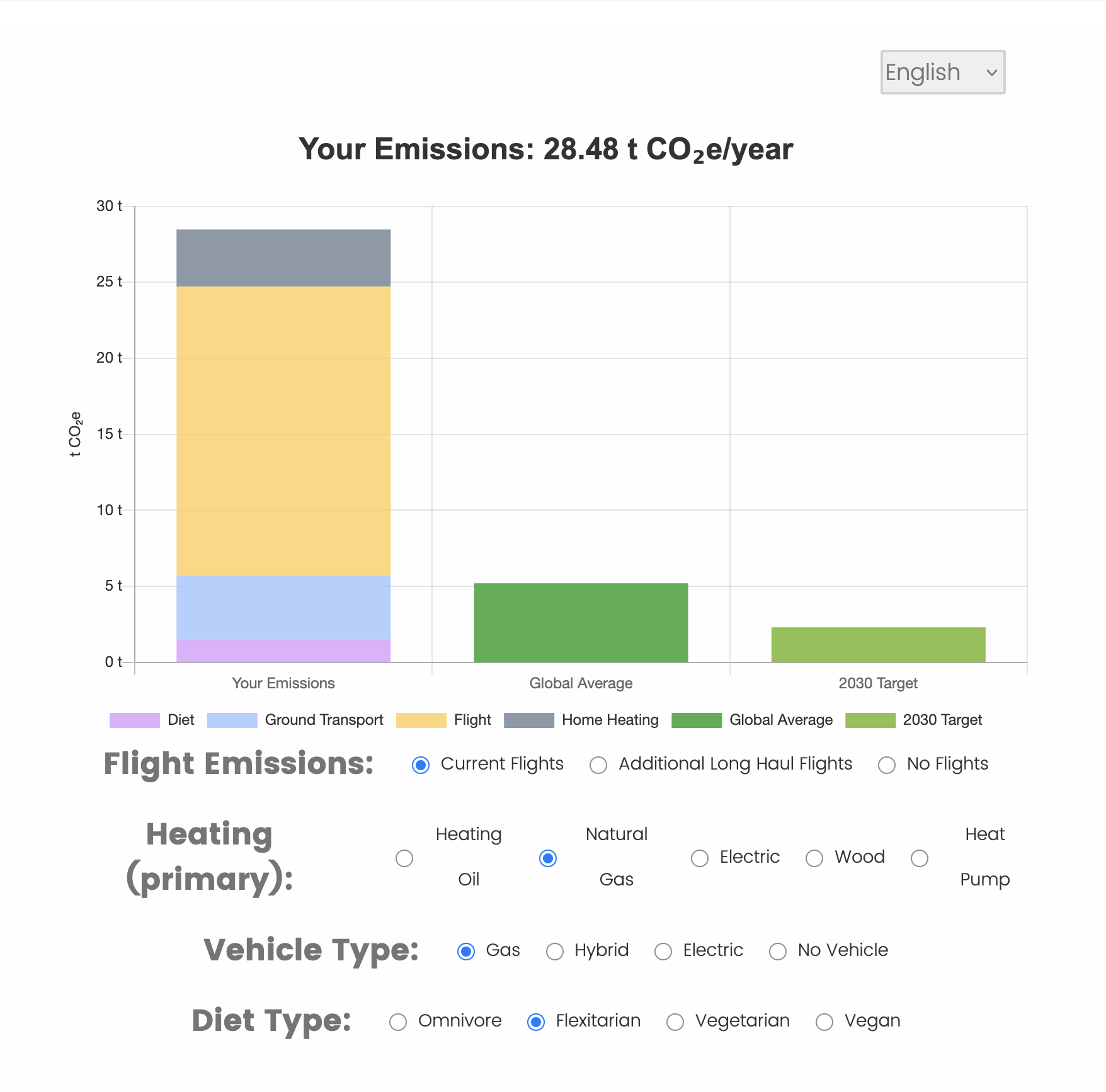
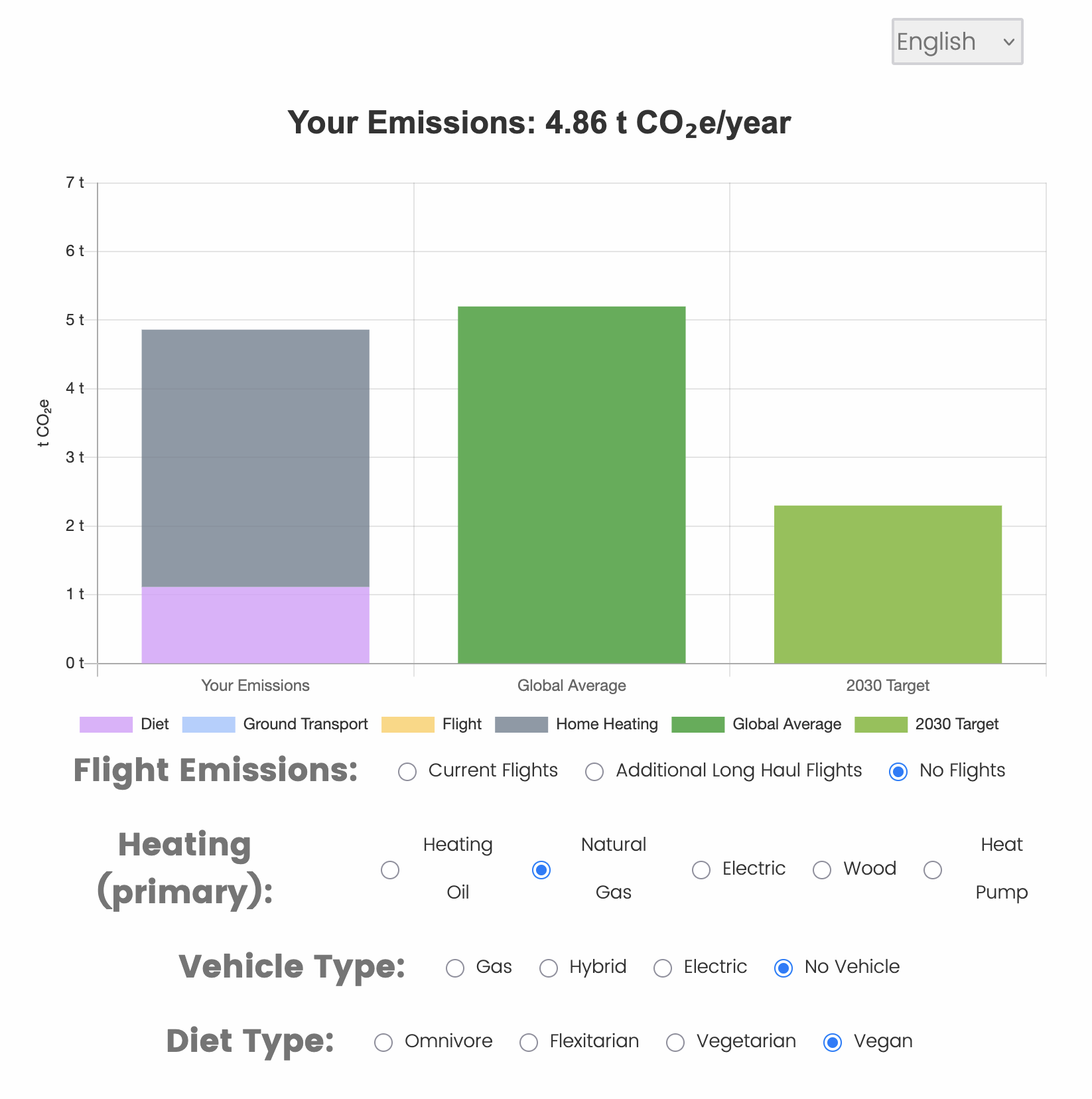
The Research Software Development team helped Hoffmann create an interactive chart based on the user’s local transportation, diet, air travel, and home heating habits. The user will be encouraged to modify their responses to see how their greenhouse gas (GHG) footprint changes. Half of the participants in Hoffmann’s experiment will be shown this interactive chart, along with other information about the effects of their personal GHG emissions. In a follow-up survey, participants will have a chance to win a vacation involving a (high GHG emissions) flight or a local (low GHG emissions) hotel stay, at various rates of carbon taxation. Their choices will shed light on the role of consumer awareness in addressing the climate crisis.
To visualize the GHG survey response within Qualtrics, the interactive charts were built using the tools and APIs provided by the Qualtrics Survey Platform. Primarily, the web technologies such as HTML, CSS, and JavaScript were used to code the advanced visualizations. This code was then embedded within the survey by using Qualtrics APIs to fetch survey data and create custom dynamic charts using the Chart.js library. Further, the user is presented with the simple yet effective UI components to modify the survey response and dynamically visualize the changes in GHG carbon emissions based on user’s energy consumption habits with respect to local transportation, diet, air travel, and home heating. The complex formulas and algorithms to calculate carbon emissions was entirely coded in JavaScript with help from some of the Qualtrics APIs to apply filters, segment data, and choose specific metrics for analysis.
-
The Energy & Emissions Research Lab (EERL), lead by Prof. Matthew Johnson in the department of Mechanical & Aerospace Engineering, is developing an innovative methane sensor, known as the VentX, to quantify emissions from key oil and gas sector sources that are currently challenging to measure, and hence challenging to regulate. Funded by Natural Resources Canada’s (NRCan) Clean Growth Program, the VentX sensor uses a tunable diode laser to optically measure the transient flux of methane from critical sources such as well casing and storage tank vents. The optical measurement approach permits field measurements within hazardous locations, allowing acquisition of quantitative data necessary to design mitigation solutions, to calculate carbon credits, and ultimately to reduce emissions. Data from the VentX are streamed wirelessly outside the hazardous zone, allowing real-time monitoring by multiple personnel at once using cellular phones or laptops.
The Research Software Development team has supported this research by designing and implementing a desktop and mobile web front end for the sensor, displaying real-time data in a user-friendly way to web-connected phones in the field. The sensor physically interfaces with LabVIEW, a systems that allows developers to retrieve real-time data from the sensors. The front end is built upon LabVIEW and displays 1Hz results, which include velocity, methane concentration, and methane emissions rate. Technologies used include: Bootstrap and JavaScript (including the jQuery and D3.js – Data-Driven Documents libraries).
-
Overview
Gathering unique data for researchers is an ongoing challenge. Databases are very expensive to purchase even though much of the data included on public companies is publicly and freely available. Obtaining and transforming that publicly available information is highly labour-intensive however, and can be costly in terms of time and funds for researchers. In this project lead by Prof. Leanne Keddie of the Sprott School of Business, we leveraged machine learning by training it to ‘read’ the publicly available information and transform it into variables that are usable for research. By doing so, we created a portal that can be used by researchers to gather and transform data from publicly available public company information in a fraction of the time and cost typically associated with the manual processes to do this.
Background
The Securities and Exchange Commission (SEC) Form DEF 14A, also known as a Proxy Statement, is a document provided to the SEC by corporate entities. This document provides detailed information about the matters to be voted on at a shareholder meeting, information about the company’s management, compensation plans, potential conflicts of interest, financial data and other significant business matters. Companies are required to file these statements with the SEC and make them available to shareholders prior to annual or special meetings. Generally, these statements are released annually, providing a regular update on corporate governance and key issues that may impact shareholders’ decisions.
Researchers can use Proxy Statements to monitor and analyze the operations and governance of large corporations. By examining these documents, researchers can gain insights into executive compensation, board composition, shareholder proposals, and other critical corporate actions such as commitments to greenhouse gas emissions reduction, or workplace safety targets. This information helps in assessing the company’s performance, potential risks, and alignment with shareholder interests. Further, by tracking these statements over time, researchers can identify trends and changes in corporate governance practices, enabling them to make informed assessments and comparisons across different companies.
Project
Given the extensive volume of text in a single Proxy Statement, let alone the 1000s released annually, analyzing them manually can be daunting. This is an ideal scenario for applying machine learning techniques, specifically topic modeling, to reduce the time researchers spend collecting data. Topic modeling is usually applied as an unsupervised learning method which identifies patterns and structures within large sets of documents. This is accomplished using Large Language Models (LLMs) which convert sequences of words (typically sentences or paragraphs) into a vector in high-dimensional vector spaces. The LLM has been trained and fined-tuned to position semantically similar sentences closer together. Groups of sentences which cluster together, known as topics, allow researchers to identify common themes within the documents. For cases where the topic is already defined and the goal is to classify documents based on the presence of this topic, a technique called supervised topic modeling is employed. A topic can be defined by supplying a set of sentences drawn from a larger set which are considered on topic, and a set of sentences which are off topic. In this way, an analysis based on a few documents in the set can be applied to a larger set.
In our project, we have developed a web application that facilitates supervised topic modeling on S&P 500 company Proxy Statements from 2015 to 2019. This tool enables researchers to analyze a subset of documents and extend this analysis to the entire set of Proxy Statements. The web app allows users to generate topics by highlighting relevant passages within a proxy statement. These highlighted sections are encoded using a fine-tuned version of the pretrained ‘all-MiniLM-L6-v2’ LLM available from hugging face. This model is trained specifically for semantic clustering applications. The encoded passages train a logistic regression classifier, which is then used to classify sentences from unseen Def Proxy Statements based on their relevance to the identified topic. This process helps researchers determine whether a specific topic is discussed in the remaining documents, significantly enhancing the efficiency and effectiveness of their analysis.
Source code:
User Interface
Back End -
The MathLab, under the directorship of Prof. Jo-Anne Lefevre from the Institute of Cognitive Science and Centre for Applied Cognitive Research, conducts research into the cognitive processes involved in numerical and mathematical abilities. Research projects are designed to explore different aspects of mathematical cognition from its development across different ages and cultures to understanding the basic cognitive processes and numeracy skills such as the retrieval and representation of mathematical knowledge. The lab receives funding from NSERC and SSHRC, and collaborate with researchers in Montreal, Winnipeg, Belfast, and Santiago, Chile. Using HubZero, and now Microsoft Teams, has facilitated our collaborations. It helps us to keep track of the materials used in the research, provides a secure online repository for de-identified data, and allows direct collaboration as we write manuscripts. We can post drafts of articles, work on them together, or sequentially, post comments and replies. As the use of Microsoft Teams increases, the lab is finding new ways to be more efficient in their joint projects. The MathLab site includes data from several large projects, each with several hundred participants. The Lab currently has researchers from six different universities, including more than 30 people, including faculty members, postdocs, graduate students, and undergraduate students all part of the MathLab Team on Microsoft Teams.
The Research Software Development team has supported this research by migrating the entire online repository for all of the lab’s research projects from a singular and unsupported content management system based on HUBZero to Microsoft Teams, a platform supported centrally at Carleton. Software Development work comprised source code for a tool available on GitHub. This command-line tool provides a mechanism to bulk-import a list of Teams members into Teams private channels, which was manually exported from the HUBZero database. Technologies used include: Python (including the Pandas and Requests libraries).
-
The impact of social media on society has been felt in a wide range of fields such as communication, politics, and marketing. Social media facilitates a rapid spread of information and ideas, fostering global awareness and mobilizing social movements. However, it also enables the spread of misinformation and the creation of echo chambers. The way thoughts and ideas are expressed or repressed through social media is a growing area of academic research, with researchers, such as Professor Merlyna Lim from the School of Journalism & Communication, examining these platforms’ roles in shaping public discourse and societal norms.
Professor Lim’s research revolves around the mutual shaping of technology and society, and societal implications of technology, particularly digital media, information technology, data, social media algorithms, and artificial intelligence. She is particularly interested in unravelling the complex relationship between these platforms and society, in relation to issues of power relations, justice/equality, democratization/autocratization, and citizen participation/engagement.
Until recently, most social media platforms made access to the data on their platforms freely accessible via an Application Programming Interface (API). An API is a set of rules and protocols that allow different software applications to communicate with each other. APIs enable developers to access specific functionalities or data from a platform, facilitating the creation of third-party applications and integrations. These APIs were utilized by third-party app developers to build tools that automated the monitoring of these social media sites, enabling researchers to study the effects of social media on society. Examples of third-party software used to automate the monitoring of social media include Netlytics and Pushshift.io.
However, in 2023, the landscape changed dramatically with the advent of large language models that were trained using data sourced from social media sites. As a result, many social media companies replaced their free APIs with fee-based ones, rendering numerous third-party monitoring applications obsolete. Despite the introduction of fee-based APIs, some platforms still offer free APIs with significant usage limitations and strict enforcement against users who exceed them.
Research Computing Service (RCS) has collaborated with Professor Lim to develop a solution to these issues. The primary goal of this initiative is to create a series of free-to-use social media monitoring tools that comply with the newly imposed API restrictions. These restrictions have necessitated a significant shift in how tasks are executed. Previously, many monitoring tasks could be completed swiftly; however, under the new limitations, these tasks must now be distributed over a much longer time frame to avoid exceeding usage limits.
The scheduling and execution of these requests are meticulously managed by the produced web application. This application plays a crucial role in ensuring that API limits are not breached, which would otherwise result in the revocation of user access. The webapp carefully monitors the data usage of each request, balancing the need for comprehensive data collection with the strict limitations imposed by the APIs. This careful monitoring helps maintain the integrity of the users’ access to the free APIs.Once a user’s monitoring request is complete, the data retrieved is stored by the webapp, and the user is promptly notified of the completion. This ensures that users have timely access to the data they need for their research or analysis. At present, the webapp supports job submissions for monitoring two of the largest social media platforms, Reddit and YouTube. This functionality enables researchers and analysts to gather valuable insights from these popular platforms while adhering to the stringent API limitations. The collaborative effort between RCS and Professor Lim through this project represents a significant advancement in the field of social media research tools in the new pay for use API environment.
-
Prof. Sana Mohsni and Ph.D. student Awais Mojai, from the Sprott School of Business, investigate how CEOs’ characteristics and personality traits shape the level of environmental commitment within an organization. To operationalize personality assessment, the researchers employ a lexicon-based approach, analyzing CEO speech for specific linguistic cues aligned with established personality dimensions.
The researchers identified Q&A section within quarterly earnings conference call transcripts as a valuable source to extract CEO speech. While these transcripts are accessible through platforms like Bloomberg and Refinitiv, the sheer volume of data, coupled with inconsistent formatting, made manual analysis impractical. This challenge precluded the use of a rule-based approach to data extraction.
To facilitate this research, the Research Computing Services (RCS) leveraged Document AI, a collection of machine learning techniques for automated text analysis. By employing machine learning and natural language processing, Document AI efficiently processes large volumes of text data.
RCS developed a Document AI pipeline to automate extraction of CEO responses to analysts’ questions from the quarterly earnings conference call transcripts. The pipeline comprised two key stages for precision and efficiency. First, the pipeline identified the CEOs’ name from the list of Q&A panelists across various document formats. Subsequently, the pipeline isolated the CEOs’ responses, including those spanning multiple pages, while filtering out extraneous content such as page headers and footers or responses from other executives.
The implementation of this Document AI pipeline transformed a previously arduous and time-consuming task into a streamlined and manageable process. Automation not only saved substantial labor but also enhanced data accuracy and consistency.
-
SigLib stands for Signature Library and is a suite of Python scripts to query and manipulate Synthetic Aperture Radar (SAR) satellite imagery. SigLib works on Windows, Mac and Linux and relies on standard geospatial open-source libraries such as PostGIS and GDAL/OGR to query and manipulate imagery and metadata. At present, SigLib supports RADARSAT-1 (2 major file formats), RADARSAT-2, and Sentinel-1 imagery. Support for RADARSAT Constellation Mission (RCM) will be added in the future.
SigLib and the underlying SigLib API is useful for anyone who wants to:
- find and download lots of SAR imagery
- generate a ‘stack’ of images of a specific region over time, in a consistent way
- generate a library of SAR signature (backscatter) statistics over both space and time
- automate the process of querying, downloading, and manipulating SAR data
- keep track of all the SAR data and associated metadata they have on their computer
SigLib is an initiative of the Water and Ice Research Laboratory (WIRL) in the Department of Geography and Environmental Studies. It will be released on Github soon as an open-source library.
The Research Software Development team supported this research by implementing the functionality of the Query mode of SigLib. This mode is used to query and download SAR imagery from EODMS (RADARSAT-1; RADARSAT-2 and RCM, for those with access) and Copernicus Hub (Sentinel-1). It can also extract metadata from local files to create a local database table of imagery to query against. Technologies used include: Python (including the psycopg2, GDAL, configparser, pandas, geopandas, sentinelsat, and eodms-api-client libraries.
-
“Rome from the Ground Up” is a SSHRC-supported YouTube social network analysis project led by Prof. Jaclyn Neel from Greek and Roman Studies. The aim of this project is to discover popular opinion about ancient Rome by analyzing amateur YouTube comments, video contents, and communities. These popular media are also compared to source material in ancient texts, modern textbooks, and mainstream fiction.
The Research Software Development team supported this research by implementing a suite of python scripts that collects metadata about a set of videos and their creators using the publicly available YouTube Data API v3.0. It also grabs videos’ comments and metadata about its commenters. Merging different types of information, the program builds a network composed of creators, videos, and commenters. This network can be visualized in the data visualization tool Cytoscape. The set of input videos can be given as a URL playlist or this set can also be retrieved by a YouTube query search using the implemented script. Technologies used include: Python (including the pandas library) and the YouTube API v3.0.
Source code:
Prof. Neel presenting preliminary results using the tools implemented here:
https://www.youtube.com/watch?v=IEC1WR4nbU8 -
Media coverage plays a crucial role in shaping public awareness and influencing policymakers’ attention to societal and policy issues. This project collects and analyzes real-time data from Canadian media sources to identify the most prominent policy-related themes in the news. It serves as a public policy resource, offering valuable insights and datasets to support students and researchers within the University Community.
The recently completed first phase of the project focused on identifying trending policy issues at specific time intervals, with automated updates. A dashboard has been developed to display these trends and track their evolution over time. The second phase will enhance this functionality by enabling real-time tracking of predefined policy issues across different provinces in Canada.This project leverages advanced artificial intelligence (AI) technologies to monitor and analyze trending topics in news media. This initiative aims to equip policymakers and researchers with valuable insights into media publication patterns and public perception of news content. By providing a comprehensive understanding of these trends, the project facilitates informed decision-making to address societal challenges effectively.
The system developed by the RCS team addresses data collection, processing, and visualization of diverse topics. It is composed of several integrated modules, including data collection, data storage, backend API, topic classification and processing, as well as data visualization.
1. Data collection
The primary data source for this project consists of media outlets across Canada. To facilitate data acquisition, the RCS team utilized the Scrapy framework to develop custom web crawlers (spiders). These spiders are designed to systematically crawl and extract news articles, capturing key information and structuring the data for subsequent storage and processing.
2. Data storage
The data is stored in a PostgreSQL database deployed within a Docker container to ensure scalability and ease of management. The database schema is designed to accommodate multiple tables, including those for storing news articles, AI-computed topics over time, and frontend configuration settings. News articles are retained indefinitely, while topic-related data is subject to expiration based on parameters configured by the frontend administrator. The structured nature of the data ensures its suitability for subsequent processing and research purposes.
3. Backend API
The system provides robust API endpoints for accessing the structured data, developed using the NestJS framework to ensure scalability, reliability, and maintainability. These endpoints facilitate seamless integration with other modules and external users, minimizing errors and enhancing system efficiency. Comprehensive documentation of the API, including endpoints and data structures, is provided through Swagger, enabling developers and researchers to quickly understand and utilize the system effectively.
4. Topic classification and processing
Data processing plays a pivotal role in this project, encompassing multiple stages and scripts that operate over time. The project incorporates four primary AI-driven tasks: article summarization, topic classification, topic naming, and topic keypoint extraction. Topic classification is achieved using the BERTopic model for advanced topic modeling, while the remaining tasks are performed by either ChatGPT or a specialized Large Language Model (LLM), configurable via the frontend settings. Currently, two LLMs are deployed: GPT4All and Mistral. Additionally, the system supports the deployment of external LLMs, with configurations managed through the frontend. At present, the Mistral model is the default LLM in use.
The Large Language Model (LLM) is utilized to generate concise summaries of news articles, which serve as input for topic classification. Additionally, the LLM is employed to extract key points for each topic from a collection of articles and to derive a representative topic name based on the most relevant keywords.
The BERTopic model is employed for topic classification by analyzing encoded representations of news articles to identify similarities and group them into coherent categories. The system supports multiple levels of categorization, allowing for varying granularity in topic classification. The default view presents a high-level overview of topics, while researchers can access three distinct levels of categorization, ranging from approximately 5 broad topics to around 50 more granular topics in the refined view.
5. Data visualization
The data visualization for this project is handled by the frontend web application designed using modern NextJS technology. The end user is presented with interesting top trending news and its insight in the form of charts/histograms and auto refreshing alert texts. These are rendered efficiently with the help of various Web UI widgets. The main challenge in architecting the frontend was to implement the auto-refresh feature where various UI widgets would poll and fetch latest trending news as soon as it becomes available, which needs to be rendered as a cascading effect to the deeply nested UI widgets. This was tackled by meticulously designed RESTful APIs and data state management cache in the frontend. This enables the web browser to perform efficiently with high responsiveness and less latency by not hogging the memory & storage of the computer or laptop at the client side.
Source code:
-
Language2Test is a language testing and teaching/learning platform, envisioned by Prof. Geoff Pinchbeck from the School of Linguistics and Language Studies, that will allow multi-site language acquisition research to be conducted and low-stakes diagnostic language testing to be administered. University student demographics in North America have changed dramatically and now include larger numbers of bilingual and multilingual students from diverse backgrounds, including international students, recent immigrants, as well as long-term residents. Commercially available language tests used for university admissions are expensive and do not provide diagnostic information. Language2Test allows language acquisition research to be scaled up which affords a more nuanced examination of individual factors, such as first language effects, previous education, and home literacy practices. The suite of test instruments will monitor reading and writing proficiency as well as vocabulary and grammar knowledge of bilingual and multilingual individuals in English and in several other languages over time. Ultimately, this research will inform advances in academic language pedagogy and provide insights into the linguistic aspects of academic subject education in general. The beneficiaries of this research will include post-secondary programs for international students (‘English for Academic Purposes’ programs) and language programs for new-comers to Canada (e.g., ‘LINC’ and ‘ESL’), French-immersion and bilingual programs in K-12 schools in Canada and elsewhere. This resource can be accessed online at language2test.carleton.ca.
The Research Software Development team has supported this research by designing and implementing the Language2Test platform as a modern web application. This project is still currently under development. Technologies used include: JavaScript (including React and Redux), Python (including Flask, SQLAlchemy and Marshmellow), PostgreSQL and Keycloak.
Source code:
-
Prof. Geoff Pinchbeck from the School of Linguistics and Language Studies has compiled a corpus of text files of closed-captions and subtitles for 50,000+ TV programs and movies. This corpus is an approximation of informal and conversation English speech which will be made available as a database for two types of linguistic searches. First, Prof. Pinchbeck’s lab plans to conduct corpus linguistics research for which this type of corpus will be a useful source of data. Second, teachers and learners of English will be able to find examples of how English is used in TV and movie scripts; this is a method of language pedagogy that is termed “Data-Driven Learning” in the research literature, and some websites (e.g., the Contemporary Corpus of American English, COCA) charge to provide such a service. Although the source software for the ‘Corpus Text Processor’ was already available as a convenient, free, downloadable application for MacOS or Windows from Corpus & Repository of Writing – ‘CROW’, the advantage of making this technology available as a command line tool allows very large corpora (such the TV and movies corpus described above) to be processed on a university VM server. If a command line version wasn’t available, processing a corpus of this size on a personal computer might take several weeks or even months of intensive processing time. Prof. Pinchbeck is grateful to everyone at Research Computing Services at Carleton University for making this possible.
The Research Software Development team has supported this research by modifying the existing code to run from a Linux command-line using the Python multiprocessing library.
-
The Canadian charitable sector employs more than 10% of the country’s full-time workforce and is estimated to contribute more than $169 billion dollars (The Giving Report 2021), to Canada’s annual GDP. However, up-to-date data on the sector is critically scarce and urgently needed. The COVID-19 pandemic painfully highlighted this gap in knowledge when urgent policy action was needed, but recent data were unavailable to strengthen the sector’s responses to the crisis and lessen the impact on its own workforce. The Charity Insights Canada Project [CICP], led by Paloma Raggo, a faculty member in the Master of Philanthropy and Nonprofit Leadership (MPNL), School of Public Policy and Administration, will ensure that policymakers, practitioners, researchers, and the general public have accurate, timely, and comprehensive information about the charitable sector in Canada. Through weekly surveys and reports, an online interactive information and training hub, and monthly policy briefs, the CICP will offer an exhaustive overview of the trends, challenges, and opportunities facing the Canadian charitable sector.
The Research Computing Services team assisted this research study proposal by building a prototype website, which can be found HERE. This website has been built using JavaScript (including the React library) and hosted using GitHub pages.
-
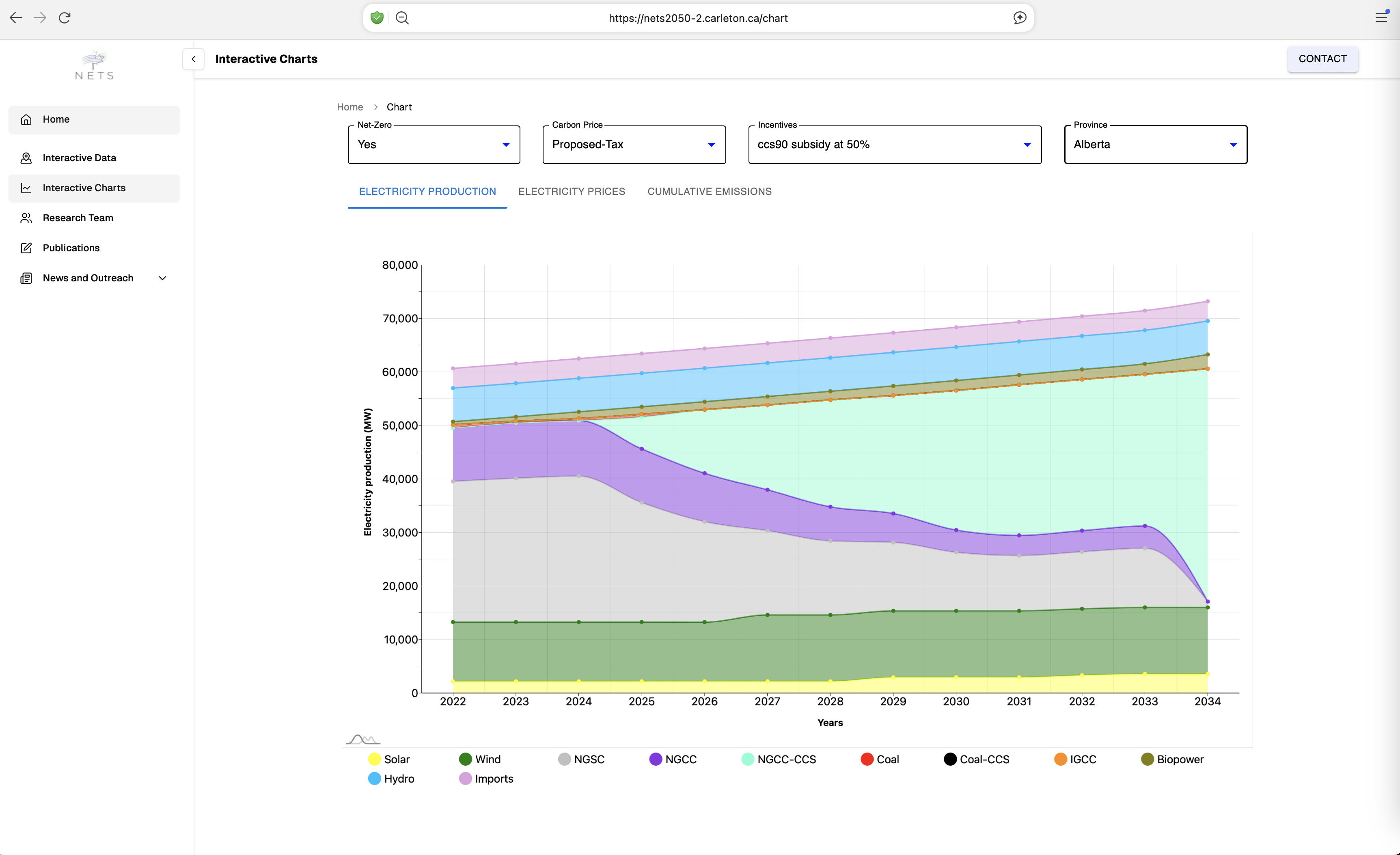
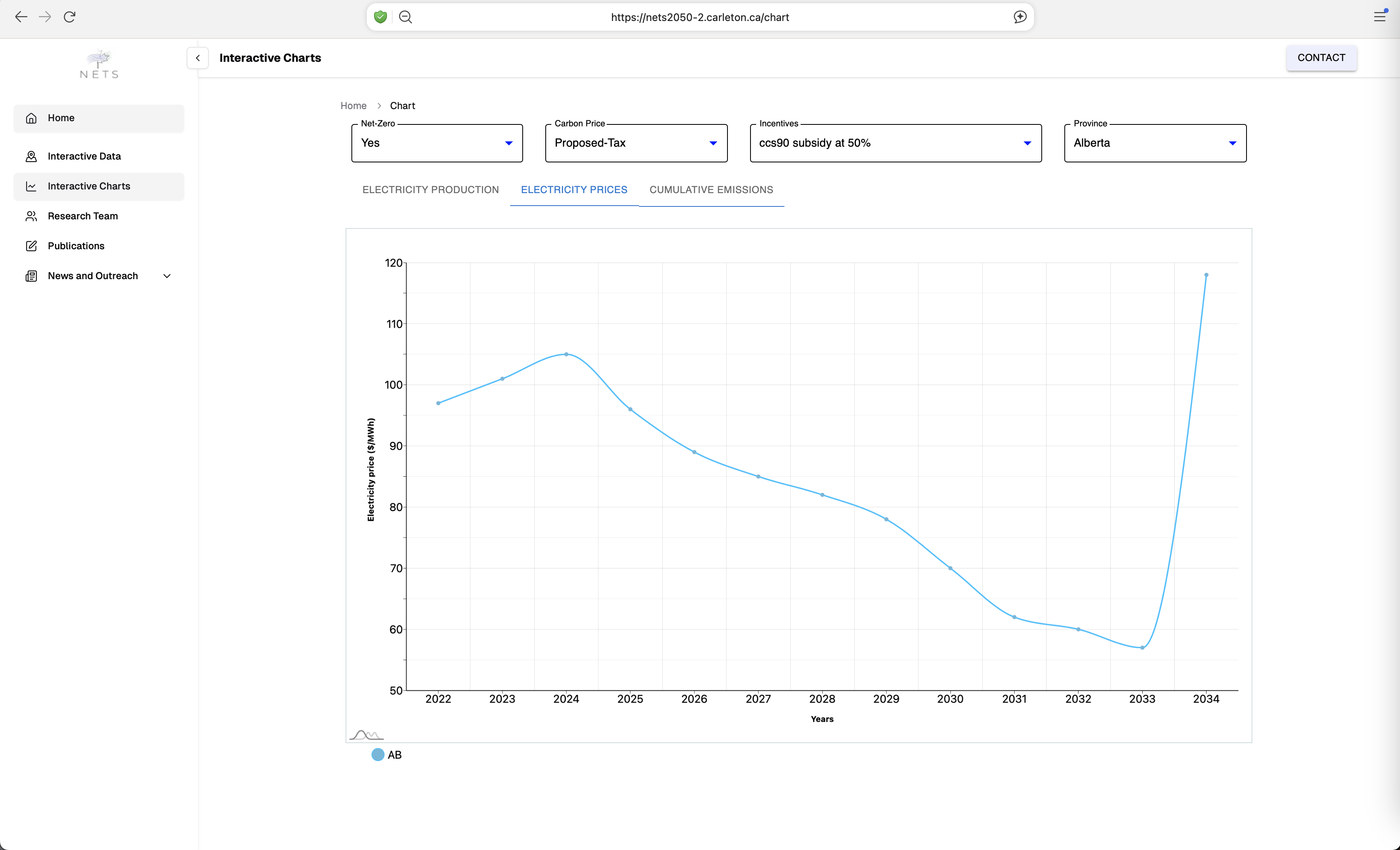
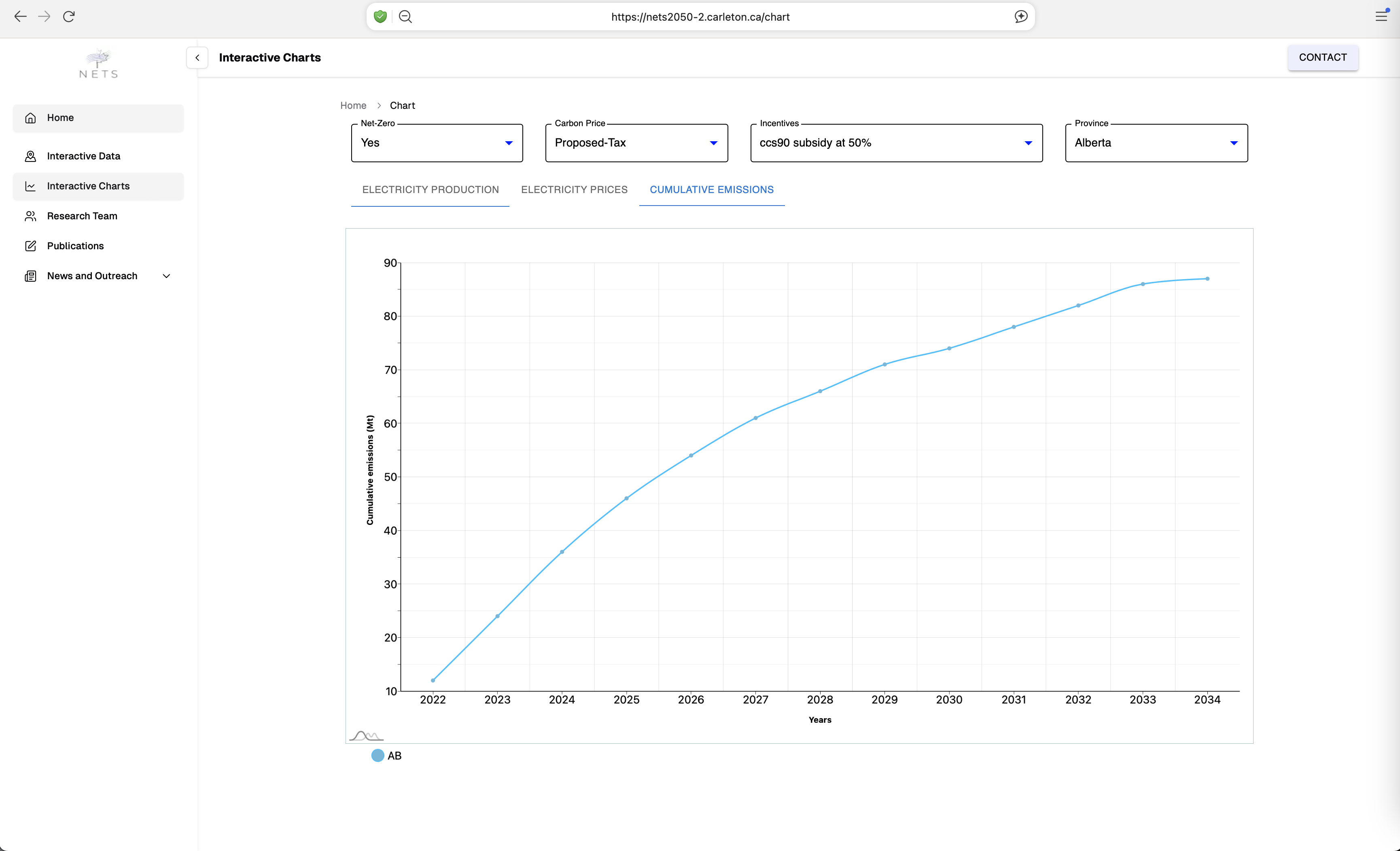
Negative Emissions Technologies (NETs) – especially direct air capture (DAC) and carbon capture, utilization, and storage (CCUS) – are becoming necessary to stabilize global temperatures at levels that avert the worst consequences of climate change. Plausible assessments of the role that NETs could play in the net-zero transition must integrate the evolution of the energy system as ambitious climate targets are adopted. This project, led by Prof Kristen Schell from the department of Mechanical & Aerospace Engineering, has developed chemical process models of NETs and integrated them into a pan-Canadian energy system model, allowing decision makers to identify near-term investment opportunities and policy makers to optimize policy portfolios that achieve real-world NETs deployment targets.
The RCS team developed a web application for the NETs project to analyze the past, current and projected, energy production trends across various industries such as Solar, Wind, Coal, Biopower, Hydro and many others. Further, the web application helps in gaining better understanding of intricate relationship between the energy production, prices, and its cumulative carbon emissions. The data filtering and visualization features of the web application allow users to explore the data in a more interactive manner, enabling them to make informed decisions based on carbon taxes and incentives across various provinces in Canada, and the impact of these factors on energy production and emissions.
Originally, the web application was developed in WordPress using PHP, HTML, CSS, and JavaScript. The legacy code and backward compatibility made it harder to adopt modern web development practices. In addition, the WordPress site was becoming slow, especially with excessive plugins and poorly optimized themes. Many features relied on third-party plugins, which lead to compatibility issues and maintenance overhead.
The RCS team decided to migrate the web application to a more robust framework, NextJS, to enhance the NETs web application performance and scalability. The migration process involved rewriting the application in JavaScript using NextJS powerful features for web development. It offers server-side rendering (SSR) and static site generation (SSG), resulting in faster load times and better performance compared to traditional WordPress setups. With SSR and SSG, NextJS ensures that pages are pre-rendered, making them more search-engine friendly. The user interactive data filtering and visualization features were implemented using ReactJS Chart library components, allowing for a more dynamic and responsive user experience. The migration also involved optimizing the codebase, reducing dependencies on third-party plugins, and improving the overall architecture of the application. In coming months, the RCS team plans to integrate additional data sources from various Canadian provinces to provide a more comprehensive view of energy production and emissions trends across Canada.
-
The Geomatics and Cartographic Research Centre (GCRC), led by Professor D. R. F. Taylor, Chancellor’s Distinguished Research Professor of International Affairs, Geography and Environmental Studies and Professor Peter Pulsifer from the Department of Geography and Environmental Studies, focuses on the application of geographic information processing and management to the analysis of socioeconomic issues of interest to society at a variety of scales, from the local to the international, and to the presentation of the results in new, innovative cartographic forms. Cybercartography is a new multimedia, multi-sensory and interactive online form of cartography and its main products are Cybercartographic Atlases which use location as a key organizing principle. These atlases create narratives from a variety of different perspectives and include both quantitative and qualitative information. They include stories, art, literature and music, as well as linguistic, socioeconomic and environmental information. The Nunaliit Cybercartographic Atlas Framework was born out of a multi-disciplinary research project in 2003 and has evolved continuously since then. It is an innovative open-source technology that facilitates participatory atlas creation and offers the means to tell stories and present research using maps as a central way to connect and interact with the data, highlighting relationships between many different forms of information from a variety of sources.
Atlascine is a unique online cartographic application based on Nunaliit. While there are a range of excellent web applications designed to tell stories with maps, Atlascine is the only one fully designed to study how we express our relationships with places through stories and to mobilize interactive maps to listen to these stories. To do so, Atlascine connects media files (i.e. video and audio) with transcripts (i.e. text) and maps via a range of tags. Atlascine is a collaborative project between The Geomedia Lab at Concordia University led by Professor Sébastien Caquard and GCRC. It has been used to develop different online atlases such as The Atlas of Rwandan Life Stories.
The Research Software Development Team supported the Atlascine project by building a new feature, called the Multi Maps Module. This module is responsible for organizing large volumes of “story data” by themes that have been assigned to them. Traditionally users would first select a story and then explore a variety of themes that it contained, but this new module would allow a user to select a theme and then explore a variety of stories that touch on this theme. This enhances Atlascine’s existing goals, allowing users to identify new patterns and structures in these stories and associate them with the places where different events took place. This new module comes with the following components: a legend, an interactive digital map, media player, media transcript and all existing CRUD functionality provided by the Nunaliit Atlas Framework. Each story associated with the theme appears in a legend located at the bottom left off the screen. When a story is toggled via the legend, locations of all the events are represented as rings of donuts on the map. These rings of donuts indicate the locations of events that have occurred for a given theme and story. Clicking a ring on the map will open and play an audio/video element (with its accompanying transcripts) starting at the very moment that the speaker is talking about the selected theme at that specific geographic location. Technologies used for this new module include JavaScript and the existing Nunaliit framework. The video below shows you a brief demonstration of the new feature and a link to the code repository containing this feature can be found here.
-
The Discrete Event System Specification (DEVS) is a hierarchical and modular simulation formalism that can be used to simulate an unlimited range of real-world systems. Its flexibility comes at a cost: increased complexity when developing simulation models, less model re-usability, and lowered adoption rates. In addition, the DEVS software environment is generally fragmented and silo-ed. Tools have been developed to support model debugging or simulation trace visualization but, they are often closely coupled to simulators and their usefulness is consequently limited. This research, lead by Prof. Gabriel Wainer of the Department of Systems and Computer Engineering, seeks to design and implement a web-based modelling and simulation environment that eliminates pressure points faced by DEVS users across the simulation lifecycle.
The Research Software Development supported this research by developing a specific user interface component for the front-end of the WebDEVS Environment. This component will allow non-expert users to easily prepare a visualization for standard DEVS models. It integrates into the existing platform to offer a seamless experience to users. The component was developed using JavaScript and HTML exclusively in an effort to be as lightweight and reusable as possible.
Source code:
-
Has social media empowered civil society, or is it contributing to the hollowing out of democracy? Around the world democracy is increasingly viewed with mistrust and disillusionment. The result has been problematic to say the least, with the traditional metrics of political participation – most notably voting, but also formal political party membership, campaign donations, involvement in community groups and general political interest – facing a severe decline throughout Europe and the Americas since the 1970s. In the case of Canada, federal electoral turnout plummeted to its lowest levels on record in 2008, reinforced by parallel trends of increasing discontent with the major political parties, a stark rise in regional and ethnic populism within party support bases, and widespread cynicism towards politics in recent years.
Yet during this same period informal political engagement online has skyrocketed. From the creation and sharing of unique content to the mobilization and articulation of ideas, the emergence of novel forms of engagement has in many ways been powered by the now ubiquitous place smart phones and social media have in contemporary life. But even as these novel forms of engagement herald new possibilities for democratic participation, novel issues such as privacy breaches and data mining, doxing, misinformation and bots herald new concerns as well. This dissertation project of Asif Hameed, supervised by Prof. Stephen White from the Department of Political Science, is a discourse analysis that seeks to examine this shift.
Using data provided by the Government of Canada’s Digital Ecosystem Research Challenge, and with the assistance of the Research Software Development team, the foundation of this project is a Twitter content analysis of tweets related to the 2019 Canadian federal election to illustrate not only the depth of e-participation on social media, but the character of that participation. By analyzing the public responses to tweets made by three different class of political information gatekeepers this project seeks to address a simple question: is this new wave of participation occurring along deliberative, democratic lines, or does it reflect the politics of what scholars are calling the post-trust era?
The Research Software Development team has supported this research by facilitating the download of millions of tweets with respect to these issues. The source code for this project can be found on our public Github page below. Technologies used include: Python (including the tqdm library).
-
In bacteria, engineered short RNAs (sRNAs) are powerful tools for studying gene function. Using engineered sRNAs, researchers can tunably knock down the expression of a specific target gene, so as to determine the effects of that gene’s loss. This is particularly useful when studying genes that are essential for survival, which cannot be knocked out using traditional techniques. The purpose of this project, lead by Prof. Alex Wong from the Department of Biology, is to create software to design sRNAs targeting user specified genes, using genome sequence information as input. This resource is available online at caren.carleton.ca.
The Research Software Development team will support this research by implementing the sRNA design algorithms selected by Prof. Wong into a tool usable by researchers on the command line as well as through a web interface. Technologies used for the desktop tool include: Python (including the Biopython and Celery libraries) and BLAST. Technologies used for the web application include: JavaScript (including React and Redux), Python (including Flask, Biopython and Celery), BLAST, and Redis.
Source code:
-
The identification of organisms from DNA sequence data requires the availability of sequences that are specific to particular groups. For example, genomic regions specific to a bacterial or viral pathogen are useful for disease surveillance. For this project, led by Prof. Alex Wong from the Department of Biology, we have implemented a pipeline to identify a set of candidate sequences that are specific to particular set of ingroup organisms (the “ingroup”), and absent in another set (the “outgroup”). The general idea behind the algorithm is as follows. We first identify all nearly identical genomic regions that are present in all of the ingroup genomes as initial candidates. We next discard any of these candidates that are present in the genomes in the outgroup. The output of the algorithm will be a set of regions that are mostly present in the ingroup genomes but not present in the outgroup genomes.
This algorithm requires the alignment tool Parsnp, BLAST and Biopython.