DEPRECATED – GPU Image CUDA 10.1 Tensorflow (2019)
Image Name
scs-gpu-cuda10.1-tensorflow
Creation Date
Oct. 31, 2019
Operating System
O/S: Ubuntu 18.04
Window Manager: XFCE
Intended Use
GPU virtual machine with tensorflow install.
This VM has been tested with the GeForce RTX 2080 SUPER card that requires NVIDIA driver greater than 418 compatible with CUDA 10.1.
This Virtual machine has been depricated and replaced by SCS Tensorflow GPU VM 2021
Account
Username:Password
student:student
Access
From outside of Carleton you will need to VPN to Carleton in order to access the VM
- VPN: Carleton VPN when connecting from outside of the campus
- x2go: download x2go client to get a full graphical desktop
- ssh: use a terminal window to gain ssh access
- console: SCS Open Stack horizon web interface (not recommended)
For the x2go config use Session Type: XFCE
Software
| Software | Version |
| NVIDIA Driver | 430.50 |
| CUDA Toolkit | 10.1 |
| cuDNN | 7.6.4 |
| NCCL | 2.4.8 |
| Tensorflow | 1.15 or 2.0 |
Tensorflow
The image has Tensorflow 1.15 installed by default. Tensorflow 2.0 is available as a pip whl package.
The tensorflow build packages are located here:
/home/student/tensorflow
There are two tensorflow version files:
tensorflow-1.15.0-cp27-cp27mu-linux_x86_64.whl
tensorflow-2.0.0-cp27-cp27mu-linux_x86_64.whl
The pip install command is:
pip install --upgrade --user /home/student/tensorflow/tensorflow-1.15.0-cp27-cp27mu-linux_x86_64.whl
Check your tensorflow version as follows:
python -c 'import tensorflow as tf; print(tf.__version__)'
Test if the GPU is available:
python /home/student/tensorflow/is_gpu_available.py
Switching Tensorflow versions
One way to switch tensorflow versions you can remove the old tensorflow install for the user. Say you want to install tensorflow 2.0 then you can do the following (assuming the student user):
rm -rf /home/student/.local rm -rf /home/student/.cache pip install -U --user six numpy wheel mock pip install -U --user keras_applications==1.0.6 --no-deps pip install -U --user keras_preprocessing==1.0.5 --no-deps pip install -U --user tensorflow_datasets pip install -U --user /home/student/tensorflow/tensorflow-2.0.0-cp27-cp27mu-linux_x86_64.whl
Then try running a tensorflow 2.0 example:
python /home/student/tensorflow/tensorFlow2example.py python /home/student/tensorflow/tensorFlow2example2.py
Testing the GPU
There is a danger that you run your program and the server is not using the GPU! Monitor the GPU and check its utilization to verify your program is really using the GPU.
This test case is a 2 step procedure:
- Run your test code
- Monitor the GPU
Open to shell windows on your instance. In one shell window run:
nvidia-smi -l
that will monitor the GPU.
The other window you can launch the pre-installed test code in the student account:
python /home/student/benchmarks-master/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=1 --batch_size=32 --model=resnet50 --variable_update=parameter_server
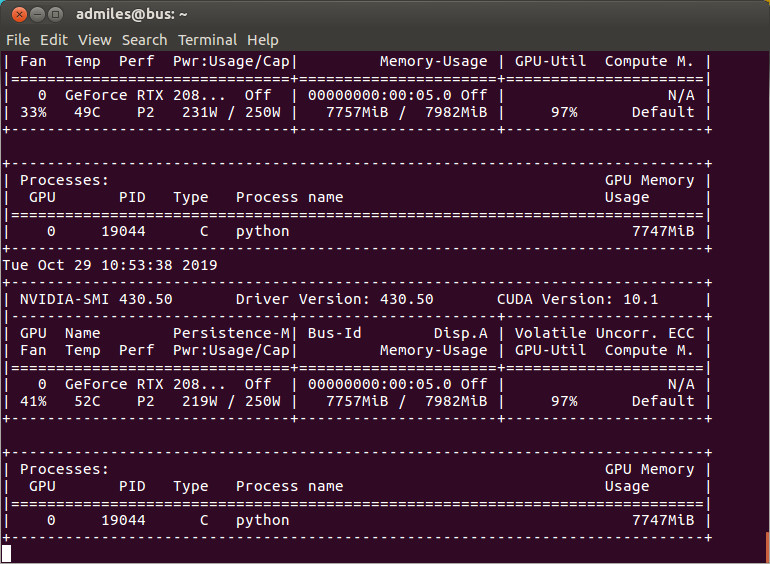
Verify that your program is being sent to the GPU and verify the GPU-Util is using the GPU, ideally at 100% utilization. In the above case its using 97% GPU-utlization
You can deviceQuery the GPU for information, its a good test if the GPU is detected on it gives you details of its spec’s. This is one of the CUDA samples:
/home/student/NVIDIA_CUDA-10.1_Samples/1_Utilities/deviceQuery/deviceQuery
The result should look something like this:
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: “GeForce RTX 2080 SUPER”
CUDA Driver Version / Runtime Version 10.1 / 10.1
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 7982 MBytes (8370061312 bytes)
(48) Multiprocessors, ( 64) CUDA Cores/MP: 3072 CUDA Cores
GPU Max Clock rate: 1815 MHz (1.81 GHz)
Memory Clock rate: 7751 Mhz
Memory Bus Width: 256-bit
L2 Cache Size: 4194304 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 3 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 0 / 5
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 10.1, CUDA Runtime Version = 10.1, NumDevs = 1
Result = PASS